
By Henrik Plate, Security Researcher, Endor Labs
This blog post presents a comparative study of the different approaches used to measure criticality and risk by a set of OpenSSF projects. Criticality is the measure of how important a package is across the global software ecosystem based on how many packages depend upon it. By combining criticality with the measure of a project’s security posture, or the risk that there may be as-yet-undiscovered vulnerabilities in software, we can prioritize the application of resources that might reduce the overall risk to the software landscape most efficiently.
This work has been taken from The State of Dependency Management, the inaugural research report from Station 9, Endor Labs’ research team. Read the full report here.
Taking responsibility, sharing efforts
Commercial software and service providers are responsible and accountable for the entirety of their solutions, both the parts developed in-house and all the upstream open source components embedded into and used by those products.
As such, they need to diligently care for their specific set of upstream open source projects, which is unique for each and every software development organization. Besides well-known and widely-used projects receiving broad attention, many users also rely on specific niche projects with much smaller user bases. Moreover, each organization faces unique security requirements, depending on their specific legal, regulatory and contractual context.
But those software development organizations also have many things in common, which is where OpenSSF steps in. The OpenSSF is a great industry effort to share the work of identifying and supporting particularly critical open source projects, creating baseline security best-practices, developing innovative security solutions, and much more.
Critical projects
But where to start? Which are the projects of critical importance for a majority of stakeholders?
OpenSSF initiatives trying to answer this question are the criticality score project and the Census II report in regards to application-level dependencies. The former uses an algorithm to compute project criticality on a scale from 0 (least-critical) to 1 (most-critical), based on several project features read through public APIs. The latter takes another approach by analyzing scan data of productive real-world applications from the private and public sectors, collected in 2020 by several commercial SCA vendors.
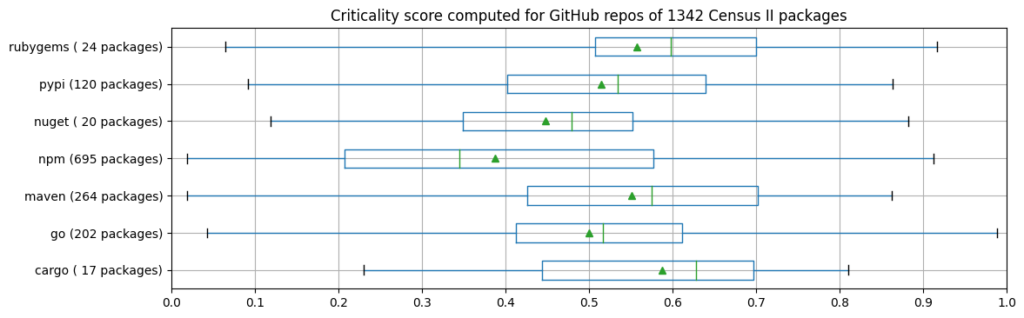
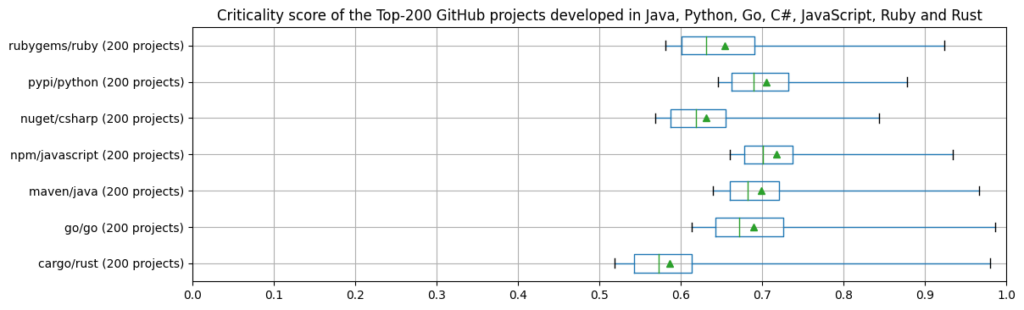
In this context, we wanted to know whether those approaches converge, thus, whether they agree on what is critical and what is not. To this end, we computed the criticality score for 1342 out of 1833 distinct packages from the Census II appendices A-H (those for which Libraries.io provided a valid GitHub repository URL), and compared those with the scores of Top-200 projects identified by the criticality score project.
The two charts below illustrate that the criticality score of projects belonging to Census II packages differs from those of the Top-200 projects in the respective programming languages. One obvious observation is that the spread is much bigger for Census II packages, with – across all ecosystems – a minimum criticality score of 0.02 and an average of 0.45 (also due to the proportionally high number of npm packages). Looking at individual ecosystems, the average and median criticality scores of Census II packages’ projects are considerably lower than those of the Top-200 projects (with the exception of Ruby/Rubygems and Rust/Cargo, both having only a relatively small sample size with 24 and 17 packages respectively).
Correspondingly, the intersection of the respective project sets is relatively small, as shown in the Venn diagrams below. Each of those diagrams shows the intersection of distinct GitHub projects (of those Census II packages having a GitHub repository URL in Libraries.io, in red) and the Top-200 projects in the respective programming language according to the criticality score project (in green). In this context, it is also interesting to see that a number of Census II packages stem from the same project: the 264 Java (695 JavaScript) Census II packages come from only 169 (576) distinct projects.
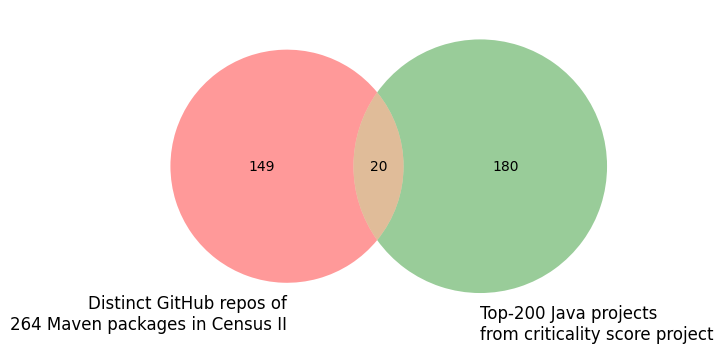
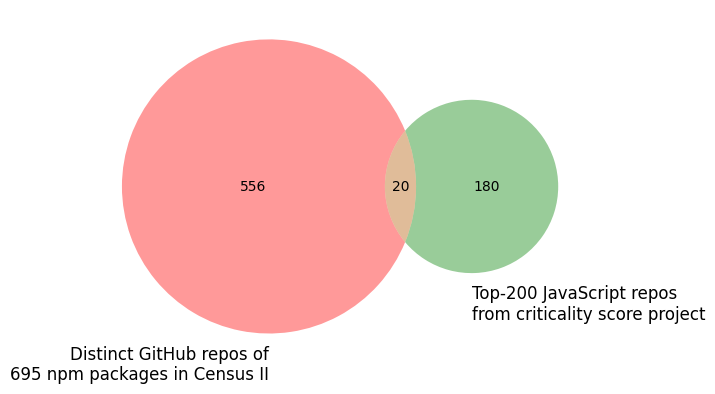
Of course, this is also due to the fact that Java and especially JavaScript projects do not necessarily deploy their artifacts on Maven Central and npm. Another reason could be that the production applications analyzed as part of Census II in 2020, potentially developed a few years before, rely on open source projects chosen in the early development phases of the development lifecycle. This explanation would be inline with the observation made in Census II that being “reliant upon scan and audit data will inherently reflect more older projects”.
Still, the box plots and the Venn diagrams show that it is anything but straightforward to develop a general algorithm to determine project criticality. Also, because some of the score’s input parameters, e.g., the count of dependents, can only consider open source dependents, not proprietary ones. All in all, those observations support the decision of OpenSSF’s Alpha-Omega project to use both initiatives, Census II and the criticality score project, as a starting point for their work.
Do my upstream projects follow security best-practices?
Open source consumers remain accountable for their software solutions. Those have specific functional requirements, which can result in unique sets of dependencies, as well as specific security requirements, depending on the legal, regulatory and contractual context.
Two OpenSSF projects support development organizations in checking the security posture of their dependencies. The best practices badge program, broader in scope by also covering non-security related topics, acknowledges the use of best-practices through badges (passing, silver, gold), and is based on self-assessments of open source project maintainers. Security scorecards rate projects from 0 (least secure) to 10 (most secure) and are solely based on publicly accessible project information, e.g., whether branch protection is enabled or whether a SAST tool is used.
The above-mentioned Census II report is meant to cover “the most widely used FOSS deployed within applications by private and public organizations”. In this respect, we found it important to check whether and how their security posture – assessed in terms of best practices badge and scorecard rating – evolved over the course of the last few years. To this end, we used a package’s source code repository obtained from Libraries.io (if any) to check whether it is registered at the best practices badge program and to compute the scorecard rating.
In regards to the former, we could not find that more projects participate or obtain badges: Census II reported 59 out of a total of 1833 distinct projects as participating in the badge program. In October 2022, for those 1413 packages that Libraries.io provided a source code repository URL, we found that 47 projects were taking part in the program, 12 having the passing badge (no silver or gold badge). For those 34 projects that were in the program both at the time of Census II and in October 2022, many self-assessments have not been updated recently (see the chart below).
![]()
For what concerns the scorecard ratings, we compared historical data (mostly from September 2021) with current ratings, and observed a noticeable improvement (see the two boxplots below). Across all ecosystems, the average (median) improved from 4.3 (4.2) to 5.3 (4.9). For Maven and npm, the two ecosystems having the largest number of samples for which a scorecard value could be computed, the average went up from 4.2 to 6.0 (Maven, 258 packages) and 4.1 to 4.9 (npm, 695 packages). With a rating of 9.2, the Python library urllib3 is the Census II package having the best scorecard rating across all ecosystems.
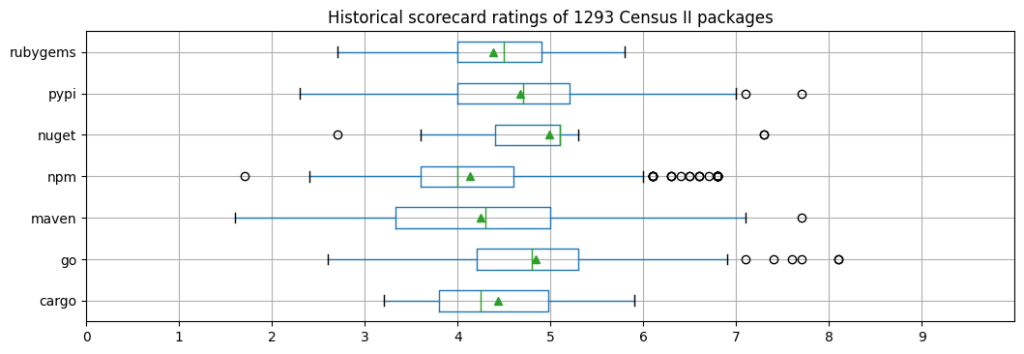
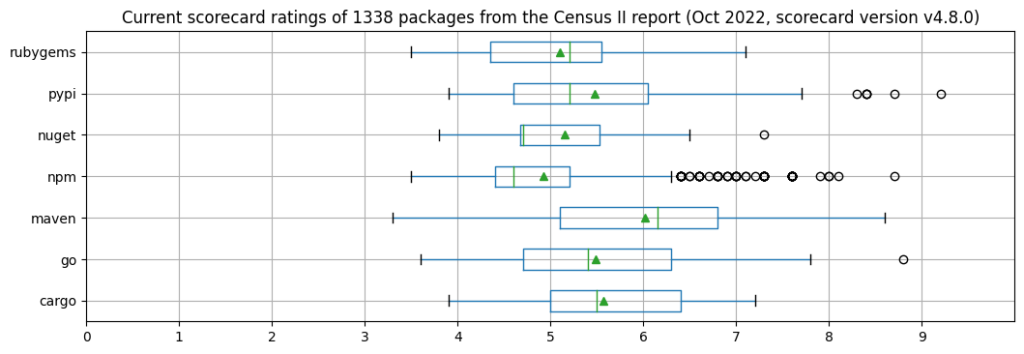
In summary, comparing the evolution of best-practice program participation and scorecard ratings, we clearly see the advantage of automated tools and algorithms over scores obtained through self-assessments.
The automated approach enables anybody to check the security posture of a given project at any time, without being dependent on a project maintainer to provide self-assessments – ideally done on a regular basis. One simple explanation for the lack of participation in the best-practice program could be that it requires effort. With many maintainers already being overwhelmed by community requests, e.g., issues or pull requests, this effort may be simply too much, especially for maintainers spending their spare time.
Conclusions
With this first research report, available for download at Endor Labs’ website, we wanted to shed some additional light on the intricacies of the software industry’s dependency on open source software, with a particular focus on the application layer. We found, as visible from the above-mentioned statistics, OpenSSF initiatives provide great insights and help observing noticeable security improvements.
The OpenSSF is an effective industry effort to take responsibility for upstream open source projects, and provides commercial and non-commercial software development organizations the means to understand and improve the security posture of open source projects and their own software solutions.
But software development organizations remain responsible and accountable for the entirety of their software solutions, including its open source dependencies. They cannot share or delegate all work to OpenSSF or other open source foundations. On the one hand because many development organizations consume specific and unique combinations of open source projects, and on the other because they have specific security requirements.