
Navigating the vast ecosystem of the Open Source Security Foundation (OpenSSF) is now as easy as floating down a lazy river. Discover our newly curated, role-based User Journeys designed to…
Read More





By Madalin Neag, EU Policy Advisor, OpenSSF
The software supply chain has reached a level of complexity where manual oversight is no longer a viable strategy for security or regulatory compliance. Modern systems depend on vast, rapidly evolving networks of components, making manual, paper-based approaches to due diligence impractical. Machine-readable, continuously generated security signals are therefore the only realistic way to support Cyber Resilience Act (CRA) due diligence at scale. These signals already exist across open source ecosystems as a natural byproduct of standard development practices, though they remain fragmented across tools, repositories, and pipelines. Crucially, these signals are best understood as mechanisms for transparency rather than assurance: they expose observable characteristics of software development and operational behavior without constituting guarantees, certifications, or transfers of liability.
This shift is driven by a need for technical accuracy. Static documentation and point-in-time attestations cannot reflect continuously evolving software systems. This limitation has been underscored by recent U.S. enforcement actions, such as Department of Justice settlements involving inaccurate cybersecurity compliance certifications, which highlight how formal attestations can later be treated as misleading when they diverge from actual system behavior, significantly increasing legal exposure.
Established approaches such as continuous compliance, evidence-based assurance, and secure-by-design all rely on the same principle: replacing subjective, point-in-time claims with dynamic, verifiable proof, automated data that reflects actual system behavior.
Within this model, roles remain clearly separated. Upstream open source projects may choose to publish security-relevant signals in machine-readable formats, while manufacturers, who bear the legal responsibility under the CRA, consume and interpret this information as part of their due diligence processes. This preserves the foundational “no warranties, no liabilities” principle of open source. Participation from upstream remains strictly voluntary and must not introduce legal obligations, certification expectations, or shifting of compliance risk and liability to the project community, ensuring that ecosystem sustainability is maintained while enabling effective downstream risk management.
This discussion builds on earlier reflections on voluntary attestation models under the Cyber Resilience Act, particularly Article 25, which enables voluntary security attestation programmes to support manufacturer due diligence for products incorporating free and open source software while preserving the separation between upstream development and downstream regulatory responsibility. From a systems perspective, however, Article 25 also exposes an important limitation of paper-based attestation approaches. Static, human-authored representations of security struggle to remain accurate within environments defined by continuous change, where rapidly evolving components and deeply nested dependencies can quickly render point-in-time attestations incomplete or outdated. This leads to a broader architectural observation: effective due diligence at scale increasingly shifts away from narrative declarations toward machine-readable, continuously updated security signals embedded directly within development and release workflows. In this framing, voluntary attestation is valuable not as a mechanism for upstream certification, but as a way to enable structured, interoperable security data that downstream systems can automatically consume and evaluate. Machine-readable signals thus become the practical substrate for operationalizing the intent of Article 25 in complex software ecosystems, preserving voluntariness, avoiding any conflation of transparency with assurance, and enabling evidence-based due diligence aligned with the dynamic nature of modern software systems.
Due diligence under the CRA must be understood as a continuous, risk-based obligation rather than a procedural formality. As clarified in the European Commission’s FAQ and further complemented via the CEN PT1 standard, it is not a checklist to complete or a document to obtain, but an ongoing responsibility carried by manufacturers placing products with digital elements on the market. Its purpose is to ensure that third-party components, regardless of origin, do not compromise the cybersecurity of the final product.
At its core, due diligence requires manufacturers to make informed, traceable decisions about the software they integrate. This includes understanding the origin and role of components, evaluating their security characteristics, and determining whether their use is appropriate within the context of the product. These activities form a continuous lifecycle process covering evaluation, integration, monitoring, and remediation. The level of scrutiny applied is inherently risk-based and contextual, and depends on the role, exposure, and criticality of each component within the manufacturer’s system.
This obligation is dynamic by nature. Software components evolve, vulnerabilities are disclosed continuously, and integration contexts change over time. Due diligence therefore extends across the entire lifecycle, requiring manufacturers to revisit earlier assumptions and adjust mitigation strategies as new information becomes available. This creates a continuous feedback loop between upstream changes and downstream risk decisions.
The regulatory expectation is that this process is demonstrable through technical documentation that allows decisions and risk assessments to be traced and verified. The emphasis is not on collecting predefined assurances, but on ensuring that decision-making remains consistent, auditable, and defensible over time.
For open source components, due diligence relies on observable project characteristics rather than formal assurances. Manufacturers assess elements such as maintenance activity, responsiveness to security reports, release practices, and the availability of structured security documentation, drawing on signals that reflect how a project is actually developed and maintained. These signals can be aggregated into continuously updated, machine-readable evidence reflecting the current security posture of both the component and its dependencies. This approach does not create any dependency on upstream attestations: under the CRA, manufacturers remain solely responsible for their assessments, while any transparency provided by open source projects is entirely voluntary and does not constitute certification or liability. Machine-readable security signals therefore function primarily as decision-support inputs within downstream risk management processes. They improve the quality, consistency, and scalability of due diligence activities, but they do not replace the manufacturer’s obligation to exercise independent judgment and accountability.
A mature ecosystem of tools already generates machine-readable signals that can support due diligence under the CRA. These signals span multiple layers of the software lifecycle, from component identification to vulnerability management and build integrity. Standards such as SPDX and CycloneDX enable structured software bills of materials (SBOMs), while frameworks like SLSA define levels of build provenance and integrity. Complementary technologies such as Sigstore provide cryptographic mechanisms to verify artifacts, and formats like CSAF and VEX support the structured exchange of vulnerability and exploitability information. Tools such as SBOM CVE Check, Dependency-Track, Syft, and Grype operationalize these standards by enabling SBOM-driven component analysis and automated vulnerability scanning, while SBOMQS provides additional validation of SBOM quality and compliance against established standards.
Within the OpenSSF ecosystem, these capabilities are reinforced by a growing set of complementary tools that standardize, expose, and operationalize security-relevant signals across different layers of the software lifecycle. Some focus on repository security posture and development practices, others on supply chain integrity and provenance, while newer systems increasingly aggregate these signals into unified, queryable models suitable for large-scale risk analysis and automated due diligence workflows. At the project governance and security posture layer, OpenSSF Scorecard provides automated checks on repository hygiene and secure development practices, while the Best Practices Badge and Open Source Project Security (OSPS) Baseline initiatives offer structured indicators of project maturity and security adoption. OpenSSF Security Insights extends this approach by introducing a standardized, machine-readable format for publishing security policies, development processes, and maintenance practices, enabling more consistent interpretation of project security posture across tools and downstream consumers. Complementing these efforts, LFX Insights aggregates operational and community signals related to project activity, contributor diversity, governance, and security posture, helping organizations evaluate the long-term sustainability and operational health of dependencies over time. Together, these tools transform otherwise fragmented repository metadata into reusable signals that support risk-based evaluation without requiring additional compliance artifacts from maintainers.
At the supply chain integrity layer, frameworks such as in-toto provide cryptographically verifiable attestations describing individual steps within software build and release pipelines, strengthening provenance visibility and artifact integrity. SBOMit builds on this model by combining SBOM generation with in-toto attestations and signed supply chain layouts, enabling verifiable component composition during the build process. Related tooling such as Protobom and Bomctl improves interoperability and operational reuse of SBOM data. Protobom provides a format-neutral intermediate representation that allows SPDX and CycloneDX documents to be transformed and consumed consistently across heterogeneous tooling ecosystems, while Bomctl enables structured manipulation, merging, and management of SBOM trees across complex dependency environments.
Increasingly, these signals are being aggregated into higher-level analytical systems capable of supporting continuous, ecosystem-scale risk analysis. GUAC (Graph for Understanding Artifact Composition) demonstrates this direction by ingesting SBOMs, provenance attestations, vulnerability reports, OpenSSF Scorecard results, and related metadata into a continuously queryable graph model. This enables dependency-aware analysis of upstream risk exposure, artifact relationships, and vulnerability propagation across software ecosystems. Architecturally, systems such as GUAC illustrate a broader shift within software supply chain security: compliance and due diligence increasingly become problems of correlating continuously generated technical evidence rather than collecting static documentation.
Additionally, tools and frameworks such as OSS Review Toolkit (ORT), Community Health Analytics in Open Source Software (CHAOSS), and OpenChain extend this landscape by enabling deeper analysis and contextual understanding. ORT integrates dependency, license, and vulnerability analysis into reproducible workflows, while CHAOSS provides metrics on project activity, health, and sustainability. OpenChain complements these by defining standards for open source compliance and supply chain governance, helping organizations establish consistent, auditable processes for managing open source use. Together, these perspectives allow manufacturers to assess not only technical risk but also organizational maturity and long-term sustainability of the components on which they depend.
This direction is also reflected in European cybersecurity guidance. ENISA’s Security by Design and Default Playbook highlights machine-readable signals as a mechanism for making security both demonstrable and verifiable within development processes. By enabling continuously generated, machine-consumable evidence that can be automatically validated and reused, this approach reinforces the shift from static documentation to dynamic, lifecycle-integrated assurance, directly supporting scalable due diligence.
European initiatives further build on this foundation by operationalizing these signals into compliance workflows. EU-funded projects such as CRACoWi, CYBERFORT, CONFIRMATE, OSCRAT, and OCCTET ingest machine-readable inputs (including SBOMs, vulnerability data, and provenance information) and transform them into risk assessments and technical documentation. These platforms demonstrate how compliance can be implemented as a continuous, automated process, reinforcing the complementarity between upstream signal generation and downstream consumption.
Taken together, these tools form an interoperable ecosystem of continuously generated signals. They already provide most inputs required for effective due diligence, demonstrating that the necessary data exists within current development workflows. This confirms a key architectural reality: compliance at scale is fundamentally a data integration problem, not a documentation problem.
A large share of due diligence-relevant information is already present within open source repositories. Security policies (SECURITY.md, security.txt), contribution workflows (CONTRIBUTING.md), release histories (changelogs), issue templates, licensing files, and repository governance practices (branch protection, maintainer authentication) collectively describe how software is developed, maintained, and secured. Together, they provide a rich baseline for assessing development discipline, update reliability, and supply chain integrity, without requiring additional compliance artifacts.
However, these signals are often distributed across heterogeneous formats and locations, making them difficult to discover and reuse at scale. Improving their visibility through lightweight structuring or simple indexing can significantly reduce friction. This is not about adding new artifacts, but about improving the accessibility of existing ones.
The viability of this model is already demonstrated in practice. Many open source projects publish structured security information as part of their normal operations. Projects such as K3s provide comprehensive self-assessments describing architecture and security considerations, while the Argo project maintains clear documentation of its vulnerability disclosure processes. Other initiatives, including Privateer and other projects within the CNCF ecosystem, expose structured security information directly within their repositories. These projects demonstrate that “CRA readiness” is essentially an extension of existing high-quality security engineering. Documenting security posture is already a well-established practice; what is missing is not the content, but a consistent way to connect that content to automated due diligence workflows.
Guidance from OpenSSF security assessments further supports this practice by helping projects think systematically about their security posture, development processes, and risk boundaries.
This becomes particularly critical at scale. Modern systems depend on hundreds or thousands of components, making manual evaluation (and reliance on manual, individualized attestations) infeasible. Machine-readable signals enable automated collection, continuous updates, and consistent analysis across dependency graphs, transforming due diligence into a reproducible computational workflow aligned with contemporary software realities.
It is critical to start with a baseline legal protection: maintainers and stewards are not “suppliers” in a commercial sense and are not required or expected to sign contracts or guarantee compliance outcomes. Under the CRA, open source projects are under no obligation to support compliance activities. Responsibility remains exclusively with manufacturers placing products on the market. This legal boundary is intentional and reflects the regulation’s effort to preserve the open source model, particularly the “no warranties, no liabilities” foundation that enables broad participation and innovation. More broadly, the legislative intent of the CRA is to protect the “long tail” of community-driven innovation, ensuring that smaller projects, individual maintainers, and informal communities are not burdened with obligations designed for commercial actors.
At the same time, many projects already choose to publish security-relevant information such as vulnerability handling policies, release processes, or build metadata. These actions improve transparency and usability for downstream users, but they do not create legal obligations, warranties, or liability. They are best understood as voluntary engineering practices that reduce friction and make projects easier to adopt within regulated environments.
A central principle throughout this model is the clear distinction between transparency and assurance. Transparency refers to voluntarily published, descriptive information about how software is developed, maintained, and secured. Assurance, by contrast, implies some form of validated guarantee, certification, or assumption of responsibility. Under the CRA and within open source ecosystems, transparency must never be interpreted as assurance.
Any attempt to interpret voluntary signals as certification risks undermining both the legal structure of open source licensing and the intent of the CRA. From a regulatory perspective, oversight remains focused on products placed on the market rather than upstream development processes. As a result, any security signals published by projects function as inputs into downstream evaluation, not as regulatory objects in themselves.
Within this framework, upstream security signals serve only as inputs into downstream due diligence. Manufacturers remain responsible for evaluating those inputs and making risk-based decisions. The availability of better signals can improve that process, but it does not shift accountability or create dependencies on upstream participation.
At the same time, the CRA introduces an important change in incentives. Manufacturers can no longer rely on passive consumption of open source components without understanding their security implications. When gaps in security signals are identified, the most effective response is not to request formal assurances but to improve the upstream ecosystem through tooling, documentation, funding, or engineering contributions. This includes supporting SBOM generation, provenance tooling, vulnerability disclosure processes, or automation of security pipelines.
This dynamic creates an opportunity for a more balanced and sustainable relationship between upstream and downstream actors. By investing in the security and transparency of the projects they depend on, manufacturers not only support their own compliance efforts but also strengthen the resilience of the broader ecosystem. This shift does not alter legal responsibilities, but it encourages a model of shared interest where better upstream practices benefit all participants without imposing new obligations on open source maintainers.
Modern software systems routinely incorporate thousands of independently evolving components, making static documentation obsolete almost as soon as it is produced. In this context, scalable due diligence cannot rely on manual, document-driven approaches. Machine-readable security signals provide a scalable alternative: continuously generated, verifiable, and aligned with dynamic software supply chains.
A scalable due diligence model therefore depends not only on machine-readable signals, but also on correctly interpreting their nature. They are evidence of behavior, not guarantees of outcome. Maintaining the distinction between transparency and assurance is what allows these signals to be useful without distorting responsibility or imposing unintended obligations upstream.
The CRA establishes a clear downstream responsibility model, but its effectiveness depends on implementation. When grounded in automation, interoperability, and continuously updated evidence, due diligence becomes operational rather than procedural. This approach builds on existing engineering practices and widely adopted tooling, enabling scalable risk assessment without imposing new burdens on upstream maintainers. This direction is consistent with ENISA’s Security by Design and Default Playbook, which emphasizes machine-readable security attestations as a foundation for demonstrable and continuously verifiable security across the software lifecycle.
Crucially, this model preserves the sustainability of the open source ecosystem. It avoids shifting liability or compliance expectations onto maintainers, while still improving transparency through low-friction, machine-readable signals. Much of the required information already exists within projects today; the challenge is not creation, but integration and consistent reuse. By treating compliance as something assembled from technical evidence rather than declared through static attestations, the process remains both accurate and adaptable over time.
Ultimately, a shift toward continuous, evidence-based due diligence ensures cybersecurity can scale alongside software complexity. It enables manufacturers to manage large dependency landscapes efficiently, supports ecosystem resilience, and fosters more meaningful upstream–downstream collaboration. Compliance is not a one-time declaration but an ongoing capability that strengthens both regulatory outcomes and the integrity of the digital infrastructure.
 Madalin Neag works as an EU Policy Advisor at OpenSSF focusing on cybersecurity and open source software. He bridges OpenSSF (and its community), other technical communities, and policymakers, helping position OpenSSF as a trusted resource within the global and European policy landscape. His role is supported by a technical background in R&D, innovation, and standardization, with a focus on openness and interoperability.
Madalin Neag works as an EU Policy Advisor at OpenSSF focusing on cybersecurity and open source software. He bridges OpenSSF (and its community), other technical communities, and policymakers, helping position OpenSSF as a trusted resource within the global and European policy landscape. His role is supported by a technical background in R&D, innovation, and standardization, with a focus on openness and interoperability.

Foundation celebrates five additional members, new cyber reasoning sandbox project, and release of v1.0.0 Python Secure Coding Guide to support open source security globally
MINNEAPOLIS – OpenSSF Community Day North America – May 21, 2026 – The Open Source Security Foundation (OpenSSF), a cross-industry initiative of the Linux Foundation focused on sustainably securing open source software, today announced five new members have joined the foundation. The OpenSSF also notes additional technical resources for Python secure coding, the first cohort of OpenSSF Ambassadors, and new projects like OSS-CRS joining the foundation’s sandbox during OpenSSF Community Day North America in Minneapolis. OpenSSF’s efforts ensure that open source remains a trusted foundation for digital innovation by addressing the technical, legal, and human elements of modern cybersecurity.
These milestones address two main converging pressures in the software ecosystem: increasingly mandatory security standards and the need to unify organizations and countries behind those standards. By providing practical resources, the OpenSSF helps projects navigate complex requirements such as the CRA. The project continues to expand its global community as well, keeping all that benefit from open source software ahead of sophisticated risks and threats.
“As the threat landscape for software supply chains becomes more complex, the need for community driven security standards has never been more urgent,” said Steve Fernandez, General Manager of OpenSSF. “The growth we’re seeing in our membership and the arrival of projects like OSS-CRS show that security is an important priority for all. The OpenSSF is providing the practical tools and guidance developers need to build more resilient software.”
New OpenSSF members include ActiveState, Aikido, Minimus, and TuxCare, who join the Foundation as General Members. The FreeBSD Foundation also joins as an Associate Member. These organizations will contribute to working groups and technical initiatives to help drive the strategic direction of the OpenSSF. By collaborating within a neutral forum, these members support the long term sustainability of the open source ecosystem.
Foundation Updates and Milestones
In the second quarter of 2026, the OpenSSF achieved several milestones to secure and support more resilient software for all:
Supporting Quotes
“The Linux Foundation and OpenSSF are where the serious work on open source security gets done. No single organization secures the software supply chain alone. Thirty years of building secure open source infrastructure is what we bring to that work, and that work is better done together.”
– Abby Kearns, CEO, ActiveState
“Open source software is the foundation of modern software development, and supporting that ecosystem has always been core to Aikido’s mission. Through projects like Safe Chain, Zen Firewall, OpenGrep, and BetterLeaks, we’re investing in practical, community-driven security tooling that helps developers build and ship software with speed, trust and confidence. We believe securing open source is a shared responsibility, and we’re proud to contribute technologies that make the broader ecosystem safer and more resilient for everyone.”
– Willem Delbare, Founder and CEO, Aikido Security
“As a critical component of the global digital infrastructure, we believe FreeBSD must be part of the security discussions shaping the future of open source. Joining the OpenSSF will enable us to collaborate with others to help protect the software the world depends on.”
– Deb Goodkin, Executive Director, FreeBSD Foundation
“Minimus is proud to join OpenSSF and work alongside its other members to help secure the open source ecosystem that allows us all to thrive. Enabling developers to build on open source components while keeping security teams happy is central to our business, and we intimately understand the responsibility we all share in achieving that goal.”
– Kat Cosgrove, Head of Developer Advocacy, Minimus
“TuxCare is pleased to be joining OpenSSF and the cross-industry effort to strengthen open-source security. For more than a decade, we’ve worked to keep open source secure and reliable in enterprise production over the long term. We see that kind of sustained reliability as essential to the trusted, secure open-source ecosystem OpenSSF envisions.”
– Igor Seletskiy, CEO, TuxCare
Events and Gatherings
OpenSSF members are gathering this week in Minneapolis at OpenSSF Community Day North America. To get involved with the OpenSSF community, join us at the following upcoming events: OpenSSF Community Day Europe (Prague; October 6) and Open Source Summit Europe (Prague; October 7-9).
Additional Resources
About the OpenSSF
The Open Source Security Foundation (OpenSSF) is a cross-industry organization at the Linux Foundation that brings together the industry’s most important open source security initiatives and the individuals and companies that support them. The OpenSSF is committed to collaboration and working both upstream and with existing communities to advance open source security for all. For more information, please visit us at openssf.org.
About the Linux Foundation
The Linux Foundation is the world’s leading home for collaboration on open source software, hardware, standards, and data. Linux Foundation projects are critical to the world’s infrastructure, including Linux, Kubernetes, LF Decentralized Trust, Node.js, ONAP, OpenChain, OpenSSF, PyTorch, RISC-V, SPDX, Zephyr, and more. The Linux Foundation focuses on leveraging best practices and addressing the needs of contributors, users, and solution providers to create sustainable models for open collaboration. For more information, please visit us at linuxfoundation.org.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see its trademark usage page: www.linuxfoundation.org/trademark-usage. Linux is a registered trademark of Linus Torvalds.
Media Contact
Grace Lucier
The Linux Foundation
pr@linuxfoundation.org

Securing the open source software ecosystem is a monumental task, and it is not one we can tackle alone. It requires collaboration, education, and passionate advocates who are willing to share their knowledge across the globe.
Today, at OpenSSF Community Day, we are beyond excited to announce the launch of the OpenSSF Ambassador Program and to introduce the 13 incredible community leaders who make up our First Cohort!
Earlier this year, we put out a call for community leaders to apply to become OpenSSF Ambassadors. The response was incredible, and reviewing the impressive backgrounds of our applicants reinforced just how dedicated our community is to open source security.
The OpenSSF Ambassador Program was created to empower passionate open source security advocates. Our Ambassadors are recognized leaders who share the OpenSSF vision of a future where open source software is secure by default.
Whether they are writing thought leadership articles, speaking at global conferences, contributing to critical working groups, or mentoring the next generation of security professionals, our Ambassadors are the dedicated champions of our community.
Over the past couple of weeks, you may have noticed the reveal of our amazing Ambassadors. Today, we are happy to present the complete lineup. These individuals bring a diverse wealth of knowledge spanning supply chain security, policy, community building, and engineering.
Please join us in welcoming:
Ben Cotton is the Open Source Community Lead at Kusari. He has been active in Fedora and other open source communities for over a decade. His career has taken him through the public and private sector in roles that include desktop support, high-performance computing administration, marketing, and program management. Ben is the author of Program Management for Open Source Projects.
Rob Kenefeck is a Field CTO at ControlPlane. He likes to talk about how Security is fundamental to DevOps and how Kubernetes often isn’t the best answer to your reliability problem. A CNCF Ambassador and organizer of KCD Melbourne and CloudCon SYD, he has spent the last several years helping enterprises navigate the intersection of platform engineering, security, and cloud transformation. He participates in the CNCF TAG Security APAC group and brings a community-first perspective to his work believing that open source is how the industry levels the playing field on security.
Ejiro Oghenekome is a Cybersecurity Professional and Open Source Advocate passionate about open source security, cloud technologies, and digital resilience in Africa and globally. She contributes to open source projects like OpenSSF, focused on strengthening awareness and collaboration around secure open source ecosystems. Her interests include cybersecurity research, open source security, and security awareness within the African tech ecosystem, with a growing focus on deepening her technical expertise and contributing to real-world security solutions.
Justin Cappos is a NYU Professor and a Creator of five Linux Foundation projects: TUF, in-toto, Uptane, SBOMit, and gittuf. His research advances are adopted into production use by Google, RedHat/IBM, VMware, Docker, Amazon, Palantir, Lockheed Martin, Datadog, Bloomberg, millions of automobiles, and other IoT devices, and are also used to protect the legal code across a variety of jurisdictions, including Washington DC, Baltimore, and the State of Maryland.
John Kjell is a Principal Consultant at ControlPlane, where he helps some of the world’s most security-conscious organizations build and assure mission-critical platforms. He is a maintainer of the Witness and Archivista sub-projects under in-toto and serves as a co-chair of the CNCF’s TAG Security. John is also actively involved in several initiatives within the OpenSSF. Prior to joining ControlPlane, he was the Director of Open Source at TestifySec and held engineering leadership roles at VMware.
Brandt Keller is a Staff Software Engineer with a passion for Open Source. He serves as a Maintainer and Technical Lead for the CNCF Security & Compliance Technical Advisory Group, a Cloud Native Ambassador, and a project maintainer within the OpenSSF for the Zarf Project. He has led and contributed to multiple foundation working groups, to include publishing artifacts to enhance end-user security.
Tabatha DiDomenico is an Open Source Security Engineer and Advocate focused on the people and practices that keep open source secure and sustainable. She’s president of Security BSides Orlando, co-hosts the GR-OSS Out podcast, and contributes to OpenSSF and FINOS projects and working groups. At G-Research, she’s part of the Open Source team, working on supply chain security, secure open source practices, and community and developer relations.
Kadi McKean is passionate about the DevOps / DevSecOps community and has been since her days of working with COBOL development and Mainframe solutions. At ReversingLabs she collaborates with developers and security researchers to help entities prioritize their open source risk, reduce technical debt, and meet compliance objectives. When she’s not working with the developer community, she loves running, traveling, and hanging out with her dog Milo.
Roman Zhukov is a Cybersecurity Expert, Engineer, and Leader with over 20 years of hands-on experience securing complex systems and products at scale. Currently Principal Architect at Red Hat, he leads open source security strategy, upstream collaboration, and cross-industry initiatives focused on building trusted software ecosystems. Previously, Roman led Product Security & Privacy for Data Center and AI software at Intel. He is a Security Champion for several open source projects and an active contributor to working groups under the OpenSSF, Eclipse Foundation, and other global initiatives.
Katherine Druckman is a senior technologist, speaker, and longtime advocate for open ecosystems. Currently Head of Community and Partnership Engagement at JetBrains, she specializes in developer experience, combining software ecosystem strategy, content strategy, and community building, grounded in a foundation of hands-on software engineering experience and proven leadership. She is a long-time open source advocate, developer, and podcaster, and is currently the host of the Reality 2.0 podcast.
Hannah Braswell is an Associate Product Security Engineer at Red Hat, focusing on proactively securing complex open source systems. With a B.S. in Computer Engineering from NC State University, she brings a deep background in microarchitecture and embedded systems to her work in the open source ecosystem. As an active contributor to several projects and Working Groups within the OpenSSF, she is passionate about pragmatic development and using automation to enhance security workflows. She currently serves as the Community Manager for the OpenSSF Gemara Project and excels at making technical concepts digestible for all audiences. Outside of her work, she enjoys traveling, hiking, and exploring art exhibitions.
Yunseong Choi Yunseong Choi is a cybersecurity strategist dedicated to resilient open source ecosystems. An adjunct Professor at Kyonggi University and lecturer at Korea University, he bridges the gap between academic research and pragmatic open source security practices. As a member of the Presidential Council on National AI Strategy in South Korea, he spearheads national initiatives for SBOM/VEX standardization and compliance automation. He actively promotes global collaboration within the OpenSSF to ensure secure, sustainable open source ecosystems for developers worldwide.
Walter Pearce is a key Leader of the Rust Foundation’s Security Initiative. Walter comes from a 14-year career in security. For the past seven years, he has specialized in offensive security in the gaming industry, leading efforts to find and mitigate vulnerabilities affecting tens of millions of players at Epic Games and Blizzard Entertainment. Before that, he was a security consultant providing penetration testing, red teaming, and code review services for many Fortune 100 companies whose foci included operating systems, languages, and embedded systems. Walter has always had a passion for technical security problems and has built his career helping craft novel solutions to new, challenging issues in security. In his spare time, Walter enjoys playing open source games. He was previously a contributor and member of the Amethyst Game Engine and a lead contributor on other open source game development projects.
You will see our Ambassadors representing OpenSSF at upcoming industry events, hosting local meetups, and creating content to help developers secure their code. Be sure to follow them on socials, and say hello if you see them in the OpenSSF Slack!
Interested in becoming an Ambassador in the future? Sign up for our Newsletter for announcements regarding our next cohort application window.

By Nigel Douglas
By now a bunch of people in the OpenSSF community might already be aware of the Malicious Packages repository, but are you using it as part of your day-to-day software supply chain security?
The OpenSSF Malicious Packages repo is the first open source system for collecting and publishing cross-ecosystem reports of malicious packages – such as dependency and manifest confusion attacks, typosquatting, offensive security tooling, protestware and more.
In the past months we have seen a rise in targeted attacks on open source upstream registries like npm and PyPI – most notably Axios and LiteLLM. These compromised, misleading or outright malicious open source software packages are the focus for this project. A centralised source-of-truth repository for shared intelligence helps the open source community understand the complete range of threats, but ultimately to prevent developers consuming software dependencies that are essentially just backdoors in your codebase.
The reports in the Malicious Packages repo use the Open Source Vulnerability (OSV) format. OSV was, as the name suggests, originally created for classifying open source software packages in JSON-formatted output for known vulnerabilities, fix availability and other security advisory information. By using the OSV format for malicious packages it is possible to make use of existing integrations, including the OSV.dev API, the osv-scanner tool, deps.dev, and build your own tools on top of these open source data sources.
A good place to start is understanding how malicious packages or malware is classified in OSV. Similar to how vulnerabilities start with “CVE-” (ie: CVE-2025-3248), malicious packages start with “MAL-” (ie: MAL-2025-6812). You can simply curl the existing vulns endpoint for api.osv.dev, but instead of using a CVE ID, use the Malicious Packages ID.
curl -s "https://api.osv.dev/v1/vulns/MAL-2025-6812" | jq .
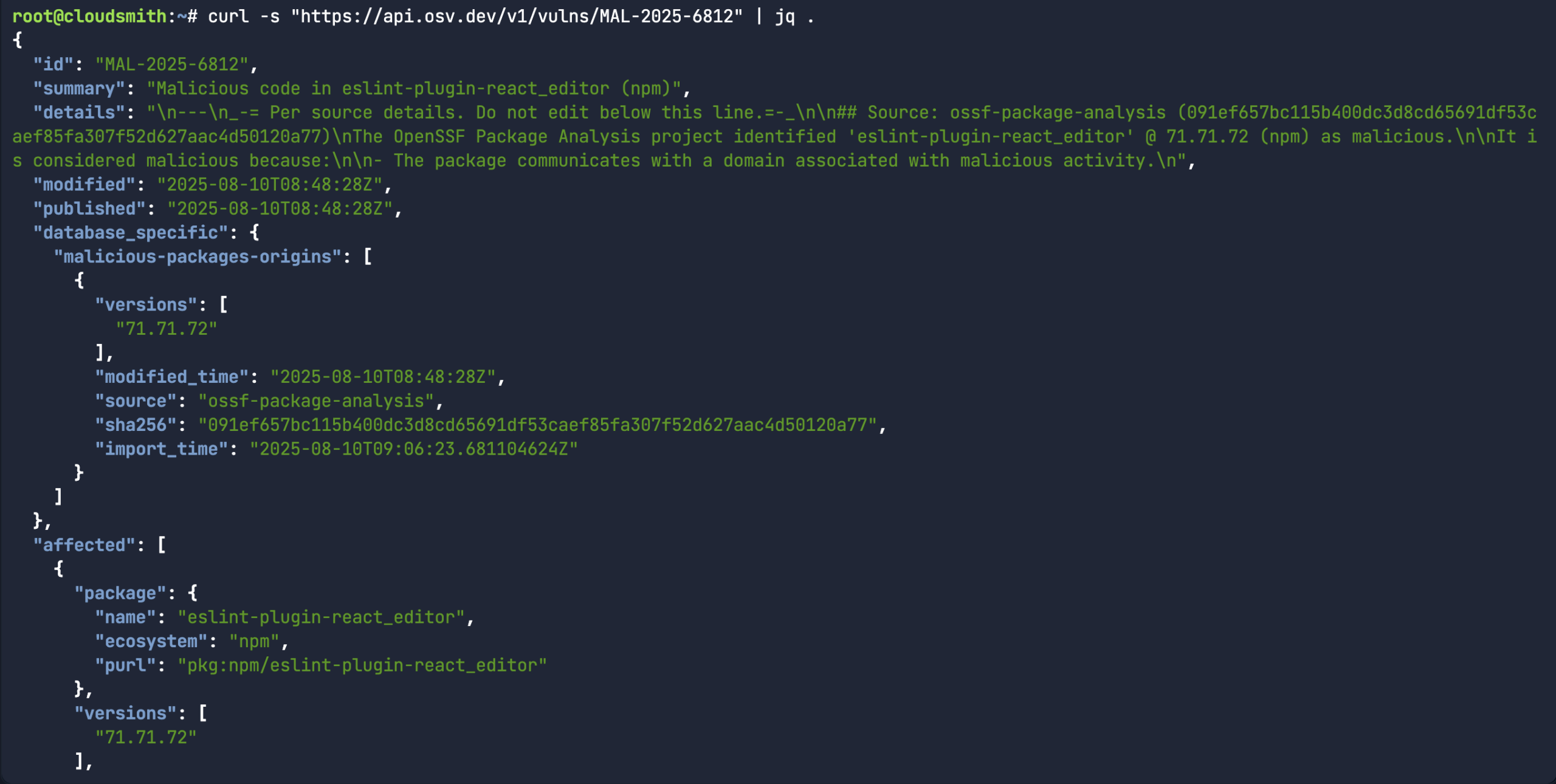 While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie: npm) to see if there’s a malicious package record associated with it.
While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie: npm) to see if there’s a malicious package record associated with it.
curl -s -d '{"package": {"name": "axios", "ecosystem": "npm"}}' "https://api.osv.dev/v1/query" | \ jq '.vulns[] | select(.id | startswith("MAL-"))'
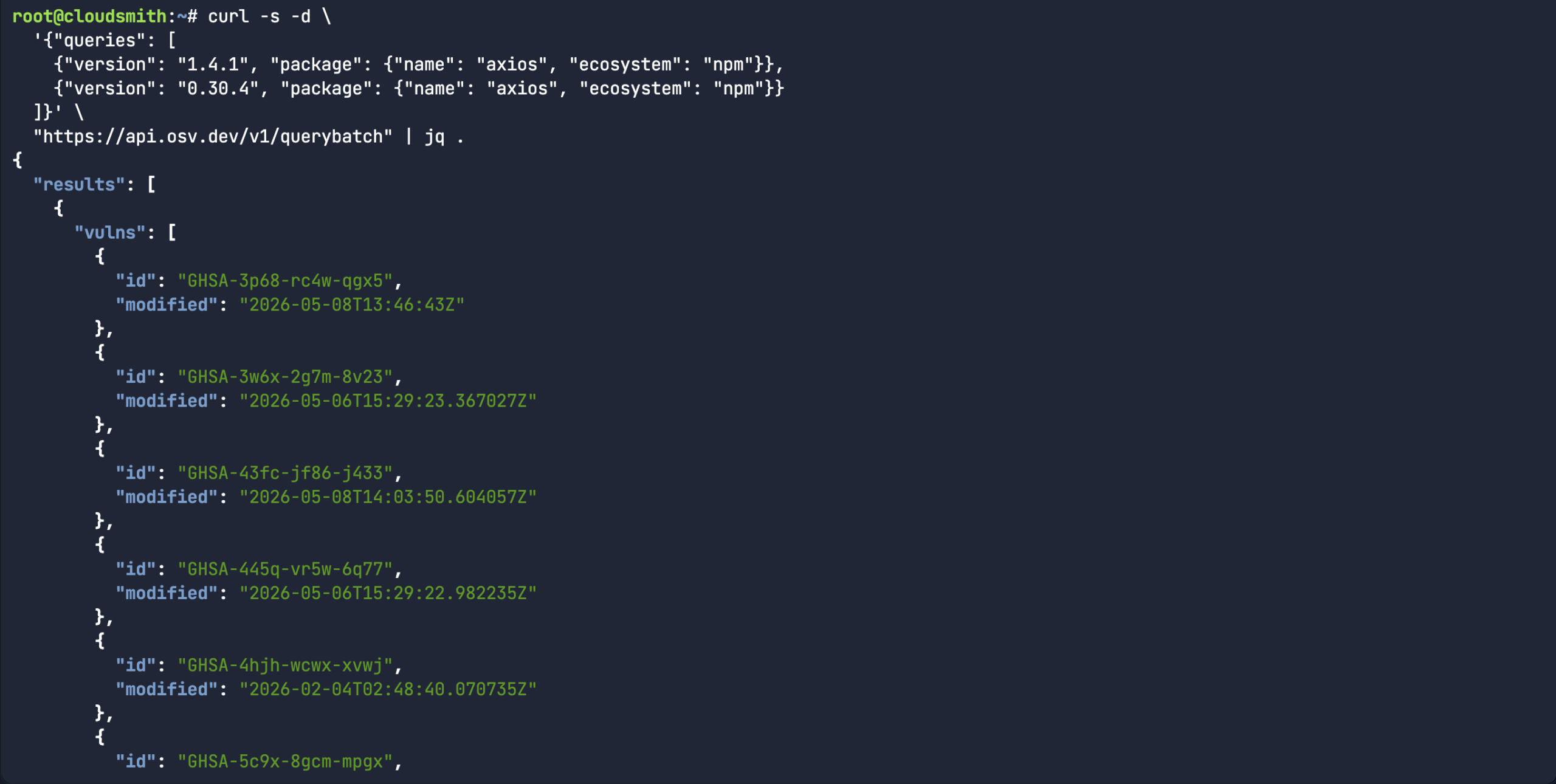
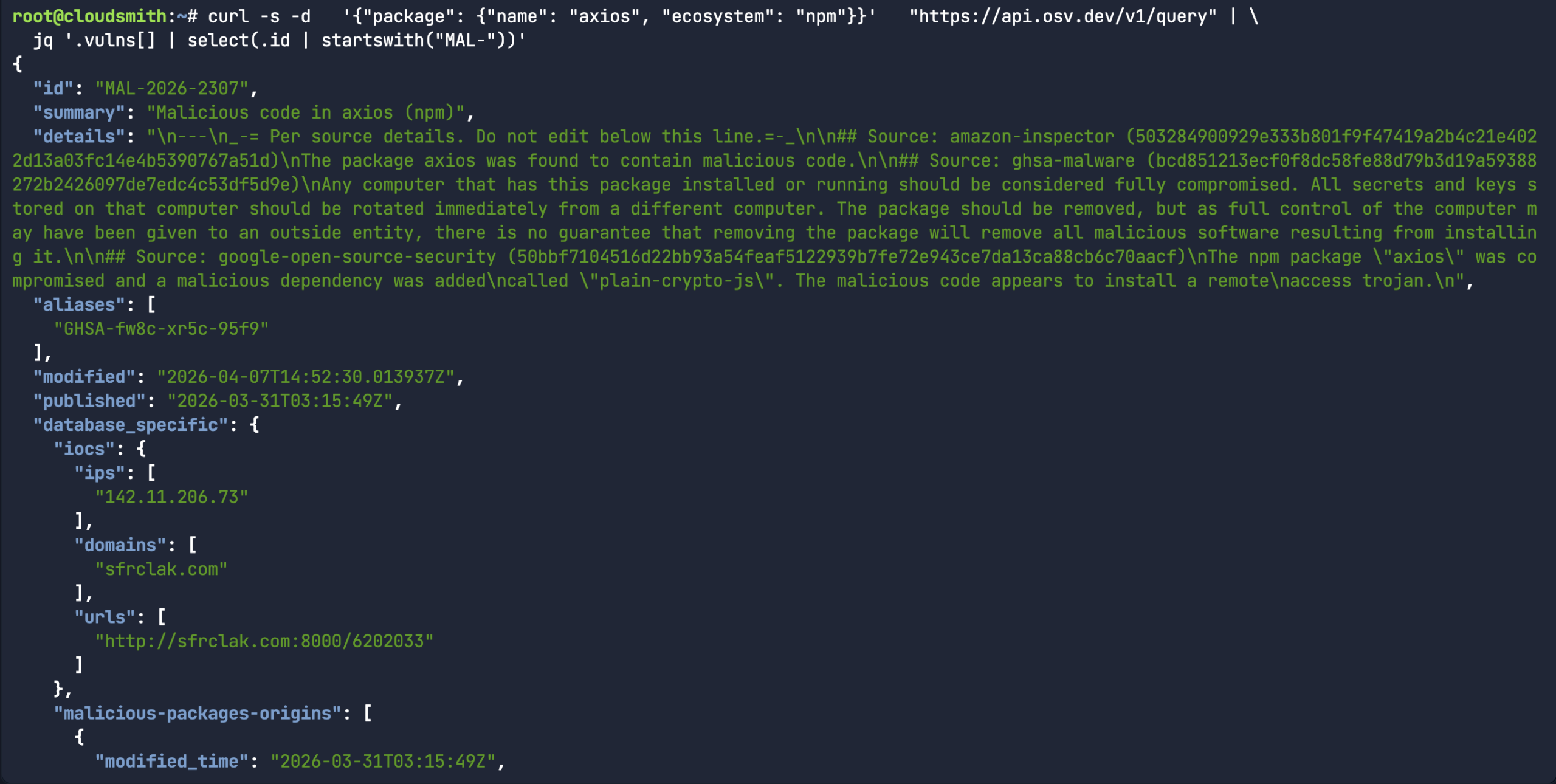 Or in the case of the Axios compromise, there were two different affected versions. Rather than scanning each version separately, you can use the querbybatch endpoint to handle multiple packages, versions and even ecosystems. In the case of MAL-2026-2307, both package versions carry the same malicious package ID.
Or in the case of the Axios compromise, there were two different affected versions. Rather than scanning each version separately, you can use the querbybatch endpoint to handle multiple packages, versions and even ecosystems. In the case of MAL-2026-2307, both package versions carry the same malicious package ID.
curl -s -d \ '{"queries": [ {"version": "1.4.1", "package": {"name": "axios", "ecosystem": "npm"}}, {"version": "0.30.4", "package": {"name": "axios", "ecosystem": "npm"}} ]}' \ "https://api.osv.dev/v1/querybatch" | jq .
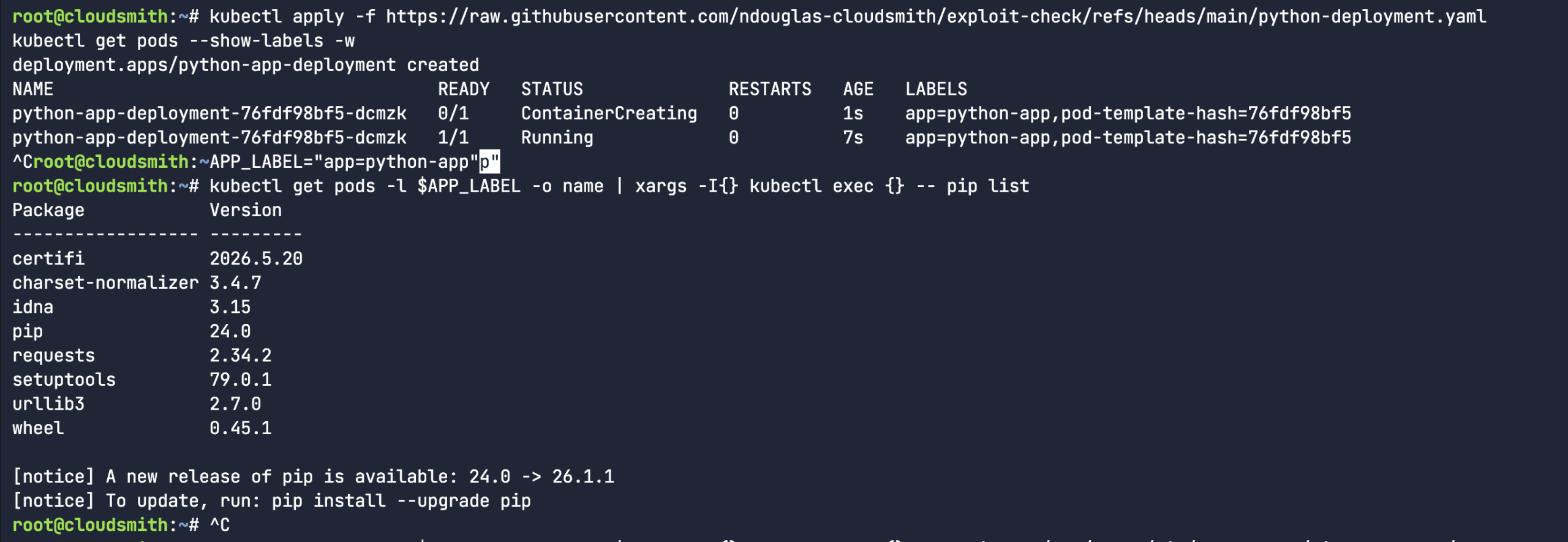
I came up with a simple osv-kubernetes.py scanner. The thought process here is that I could create a simple python-based Kubernetes deployment manifest. This pod has a list of Python packages in the filesystem of the pod, as seen when I run the pip list command.
 So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom osv-kubernetes scanner script will pick it up.
So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom osv-kubernetes scanner script will pick it up.
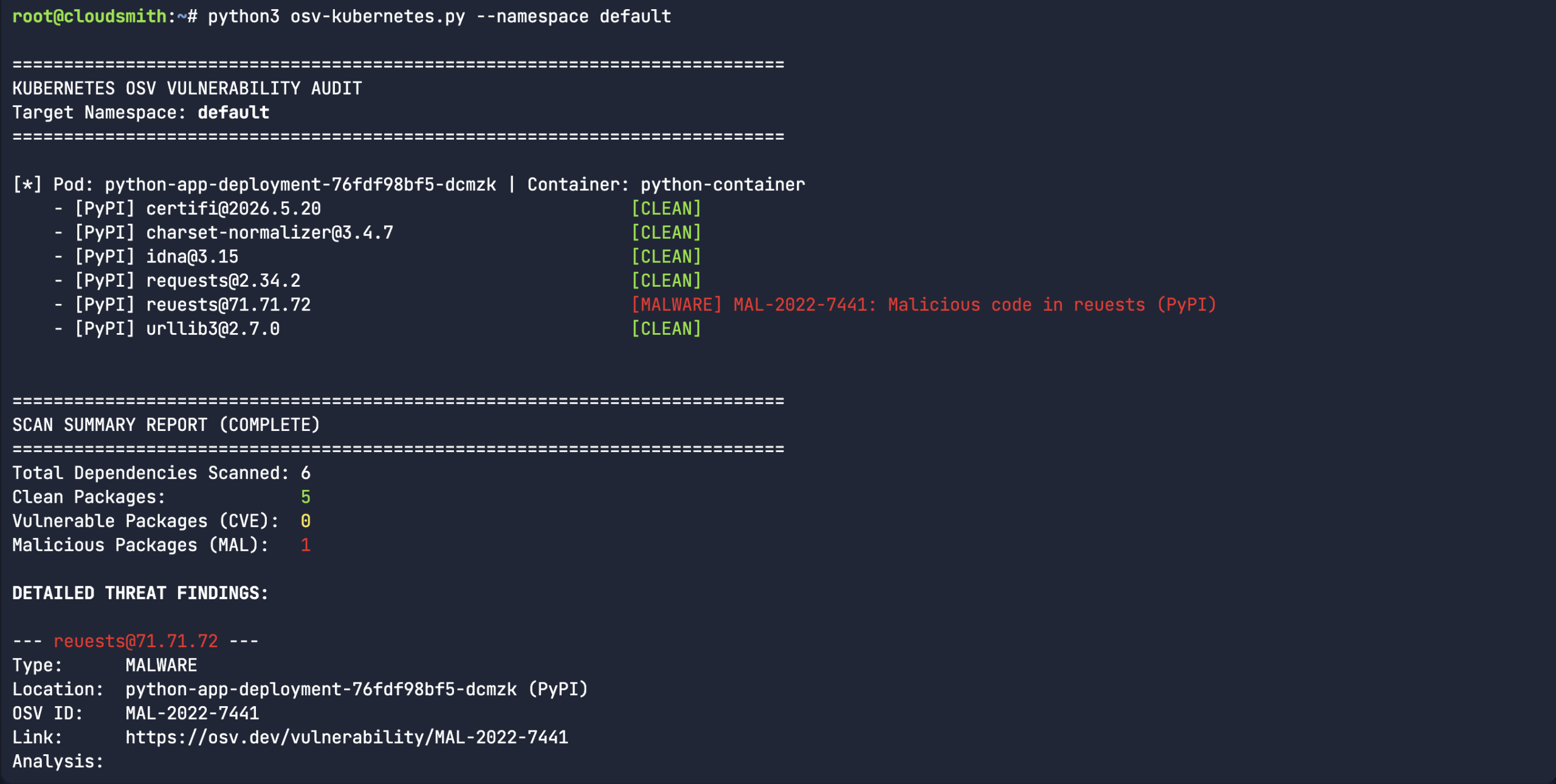 So, we created a fake typosquatted Python package. “Reuests” instead of the legitimate “Requests” library. All versions of the typosquatted Reuests library are tracked under MAL-2022-7441. While this is a simple experiment, it takes us beyond the manual process of scanning each library name and version, and automates it by piping the output of the pip list command into the API query. There are many ways that users can use the OSV API, this was purely an experiment for Kubernetes workloads.
So, we created a fake typosquatted Python package. “Reuests” instead of the legitimate “Requests” library. All versions of the typosquatted Reuests library are tracked under MAL-2022-7441. While this is a simple experiment, it takes us beyond the manual process of scanning each library name and version, and automates it by piping the output of the pip list command into the API query. There are many ways that users can use the OSV API, this was purely an experiment for Kubernetes workloads.
While there are certainly use-cases for building your own custom scanners, like what we did with the Kubernetes pod scanner earlier, I would recommend using the official OSV-Scanner to find existing vulnerabilities and malicious code injection affecting your project’s dependencies. OSV-Scanner provides the officially supported frontend to the OSV database and CLI interface to OSV-Scalibr that connects a project’s list of dependencies with the vulnerabilities that affect them.
In the below scenario, I used syft to create a simple Software Bill of Materials (SBOM) in JSON output based on an existing Python requirements.txt file. As we found out earlier, the OSV API is entirely JSON-structured, so we wouldn’t scan unstructured .txt files. The most common file to scan would be the SBOM or lock files (ie: osv-scanner –lockfile=package-lock.json).
syft packages requirements.txt -o cyclonedx-json=sbom.cdx.json osv-scanner -L sbom.cdx.json
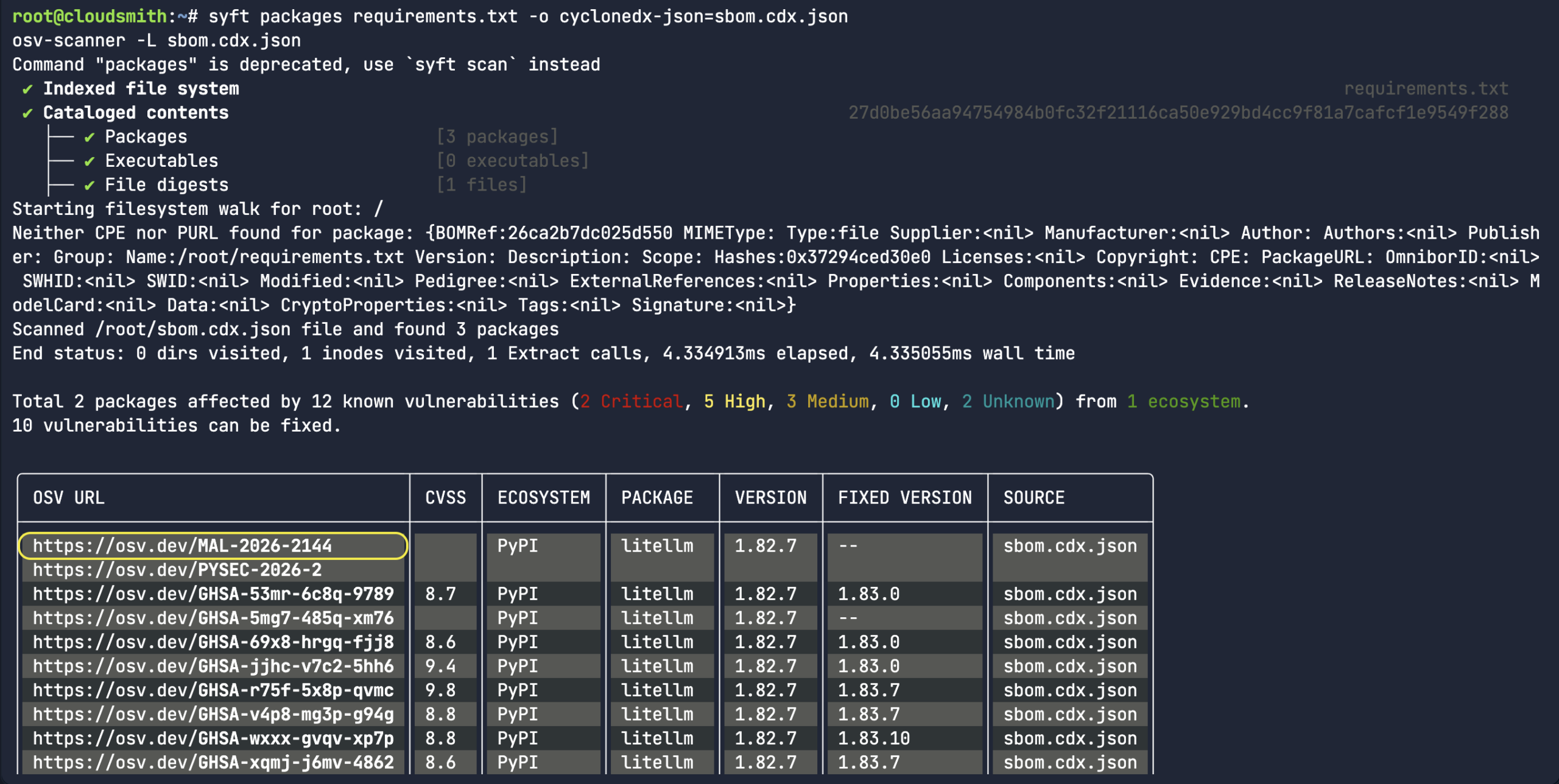
As you can see from the screenshot, the CycloneDX SBOM is successfully sourced. The packages LiteLLM and requests were correctly identified as being from the PyPI ecosystem since the Python requirement.txt file was converted into SBOM. As well as having multiple security advisories related to an upstream compromise, LiteLLM was corrected marked as malicious – MAL-2026-2144.
Again, this process is good and all, but you really need to integrate it into the CI/CD process. The OSV-Scanner Github Action leverages the malicious packages repository and the OSV-Scanner CLI tool to track and notify you of known malicious packages across the existing languages and ecosystems. The most common workflow for Github triggers a scan with each pull request and will only report new instances of malware introduced through the PR. The Github Action compares a scan of the target branch to a scan of the feature branch, and will fail if there are new vulnerabilities or malicious packages introduced through the feature branch. Alternatively, this process can be achieved on Scheduled Scans using a cron job.
I say this a lot, but in light of the recent axios@1.14.1 compromise, please make sure you always commit your npm project with the package-lock.json file. It is the only version-locking enforcement mechanism that exists in npm today. Developers should be using npm ci instead of blindly using npm install on Javascript libraries sourced from npm. The npm ci command will only work if a package-lock.json file exists. These lockfiles can also be easily scanned, as seen with osv-scanner.
Likewise, if you need to update or pull new packages from open source registries like npmjs.com, it’s also worth using the –min-release-age flag (available since npm v11.10.0) to make sure you only install updates, which are at least 3 days old (ie: npm install –min-release-age=3). Most open source malicious packages end up getting classified by OSV.dev within the first 3 days, so configuring a cooldown period is perfect to help prevent consumption of unknown or new variants of malware campaigns.
You can literally hardcode this setting (min-release-age=7) into your .npmrc file. There will always be more malicious actors attacking popular npm and PyPI packages in the future. Thankfully, most will get caught in the first 24 hours, in part due to the fantastic work going on within the OpenSSF Malicious Package packages project. I’m not trying to say that the Javascript (npm) and Python (PyPI) ecosystems are broken by design, but we certainly cannot apply blind trust to the software supply chain.
Get Involved: Help Us Secure the Ecosystem
The strength of the OSV project lies in its community. You can help protect the open source landscape by:
 Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.
Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.

By Christopher (CRob) Robinson, OpenSSF
For the better part of two years, discussions surrounding the European Cyber Resilience Act (CRA) have been somewhat theoretical: mapping requirements, debating definitions, and analyzing how the requirements will impact our amazing ecosystem. But folks, it’s mid-2026, and the CRA is live. Theory is officially in the rearview mirror as implementation milestones roll out over the next two years.
I’ve just finished reviewing the finalized 2026 CRA Awareness and Readiness Report, a joint effort with LF Research experts, and to be blunt, the results are a sobering reality check. Despite tireless community work, the broader ecosystem is far from ready for CRA compliance.
The most disappointing finding is that awareness surrounding this regulation has decreased year-over-year. Today, 66% of respondents remain unfamiliar with the CRA, a slight increase from 62% in 2025. That means a growing portion of the software ecosystem is unaware of a regulation with global consequences and hefty fines.
The geographic disparity is even more alarming. In the United States and Canada, nearly 72% of respondents are unfamiliar with the regulation. It cannot be understated: if you are a North American company selling software products into the EU market, you are legally required to comply with the CRA. However, the majority of the neighborhood is still walking unprepared toward a September 2026 reporting deadline.
For years, organizations have treated open source like a free lunch: grabbing code and assuming the lights are being kept on by someone else. Under the CRA, that posture is no longer tenable. Manufacturers now bear the legal responsibility for the security of the components they integrate. For some (read: most) this is a stark wake up call.
Despite that, 51% of manufacturers still passively rely on upstream projects for security fixes. In the new world of the CRA, “passive” is a level 10 risk.
Many of you have tried to dodge the upstream journey by maintaining private forks, but inefficient code is still inefficient code, and now we have the bill to prove it. The report shows that maintaining private workarounds is a massive form of technical debt, costing organizations an average of $258,000 in labor every single release cycle. With some release cycles as short as a matter of hours, these costs can quickly get out of hand.
For large organizations (5,000+ employees), this burden exceeds 11,152 labor hours per cycle. Maintaining these divergent codebases is a giant bill for a strategy that actually makes supply chain transparency worse. Contributing fixes upstream isn’t just being a “good neighbor” – it’s the only financially rational path forward.
For the last several years, the OpenSSF community has observed traditional vulnerability disclosure systems buckling under the strain of volume of discoveries being reported through them. Data from the report points to a surge of 394% increase in Common Vulnerabilities and Exposures (CVEs) and an 811% spike in vulnerabilities that fall within the High+ severity categories in the first quarter of 2026. Several factors contribute to this trend:
Globally, regulations like the CRA are codifying long-standing security guidance into law. This shifts security from a “nice-to-have” recommendation to a legal requirement backed by heavy non-compliance fines.
On the bright-ish side the data reveals a clear correlation: organizational diversity is a strong predictor of a project’s security posture. When more organizations invest in a project, that project becomes more resilient, making upstream investment a direct catalyst for your own compliance posture. Organizations have an important role in their own security health through their participation in open source projects.
However, the participation of small and medium-sized enterprises (SMEs) is crucial to the entire ecosystem, they are the backbone of the industry. Currently, over half of European SMEs remain unfamiliar with the CRA, creating a significant gap in project diversity. Directed investment in SME engagement is essential to prevent compliance from becoming a structural barrier to innovation. By funding the support and tools these smaller players need to remain compliant, we ensure the entire upstream supply chain remains robust and competitive.
While we wait for the full 2026 report to drop, the tools to succeed already exist. Our previous research, Unaware and Uncertain: The Stark Realities of Cyber Resilience Act Readiness in Open Source, highlighted these same gaps a year ago. It’s time to start acting. The tools to succeed already exist and practitioners who find our resources rate them highly:
This ecosystem is rife with the talent and the collaborative instincts to meet this challenge. The December 2027 deadline is a forcing function, but it’s an opportunity to build a software supply chain that is actually secure by design.
Europe is leading the way in protecting consumers globally. Despite our geographic distance in the U.S., the oceans between us all do not provide isolation from this regulation any longer. Software and products with digital elements are built with hardware, software, and firmware created through international collaboration. That fact feeds the global economy and makes manufacturers globally responsible for CRA adherence. Events that happen “over there” DO truly affect everyone.
The results of the CRA research conducted with our peers in LF Europe is truly grave. A significant amount of work and collaboration has occurred across the ecosystem since CRA enforcement. It is shocking to look back at all this work done by both the OpenSSF and its partners and see that 39% of manufacturers, who have BILLIONS of euros at stake in potential non-compliance penalties, are still unaware and uncertain about their requirements.
The next stage in our shared journey together unfolds in September 2026 when the vulnerability reporting obligations are enforced. There is not much time to prepare. Organizations have a narrow window to audit their upstream dependencies and establish the processes needed to report and patch new vulnerabilities as they emerge. The more complex aspects of the CRA are currently a year out, coming due December 2027. Please, take action today to protect yourselves, your companies, the upstream maintainers on whom you depend, and your customers.
The OpenSSF encourages everyone that benefits from open source software to consider the beauty and complexity of the open software world. Every day in software repositories, chat channels, and mailing lists a talented cohort of developers co-engineer the tools you use and love. We ask that organizations and their leaders understand that free software is NOT free. Being a responsible consumer and participant in the ecosystem creates benefits for everyone. With CRA in our midst, there is ample opportunity to make this shared space better and more secure for everyone. My hope is that we can rise to that opportunity.
Be the first to read the 2026 CRA Research Report. Subscribe to our newsletter for an alert when it releases the week of June 9 (European Open Source Security Forum in Brussels).
Get involved with the OpenSSF Global Cyber Policy Working Group.
 Christopher Robinson (aka CRob) is the Chief Technical Officer and Chief Security Architect for the Open Source Software Foundation (OpenSSF). With over 25 years of experience in engineering and leadership, he has worked with Fortune 500 companies in industries like finance, healthcare, and manufacturing, and spent six years as Program Architect for Red Hat’s Product Security team.
Christopher Robinson (aka CRob) is the Chief Technical Officer and Chief Security Architect for the Open Source Software Foundation (OpenSSF). With over 25 years of experience in engineering and leadership, he has worked with Fortune 500 companies in industries like finance, healthcare, and manufacturing, and spent six years as Program Architect for Red Hat’s Product Security team.