
In 2025, Linux Foundation Research, Linux Foundation Europe, and Open Source Security Foundation (OpenSSF) published Unaware and Uncertain: The Stark Realities of Cyber Resilience Act Readiness in Open Source. It…
Read More



By Nigel Douglas
By now a bunch of people in the OpenSSF community might already be aware of the Malicious Packages repository, but are you using it as part of your day-to-day software supply chain security?
The OpenSSF Malicious Packages repo is the first open source system for collecting and publishing cross-ecosystem reports of malicious packages – such as dependency and manifest confusion attacks, typosquatting, offensive security tooling, protestware and more.
In the past months we have seen a rise in targeted attacks on open source upstream registries like npm and PyPI – most notably Axios and LiteLLM. These compromised, misleading or outright malicious open source software packages are the focus for this project. A centralised source-of-truth repository for shared intelligence helps the open source community understand the complete range of threats, but ultimately to prevent developers consuming software dependencies that are essentially just backdoors in your codebase.
The reports in the Malicious Packages repo use the Open Source Vulnerability (OSV) format. OSV was, as the name suggests, originally created for classifying open source software packages in JSON-formatted output for known vulnerabilities, fix availability and other security advisory information. By using the OSV format for malicious packages it is possible to make use of existing integrations, including the OSV.dev API, the osv-scanner tool, deps.dev, and build your own tools on top of these open source data sources.
A good place to start is understanding how malicious packages or malware is classified in OSV. Similar to how vulnerabilities start with “CVE-” (ie: CVE-2025-3248), malicious packages start with “MAL-” (ie: MAL-2025-6812). You can simply curl the existing vulns endpoint for api.osv.dev, but instead of using a CVE ID, use the Malicious Packages ID.
curl -s "https://api.osv.dev/v1/vulns/MAL-2025-6812" | jq .
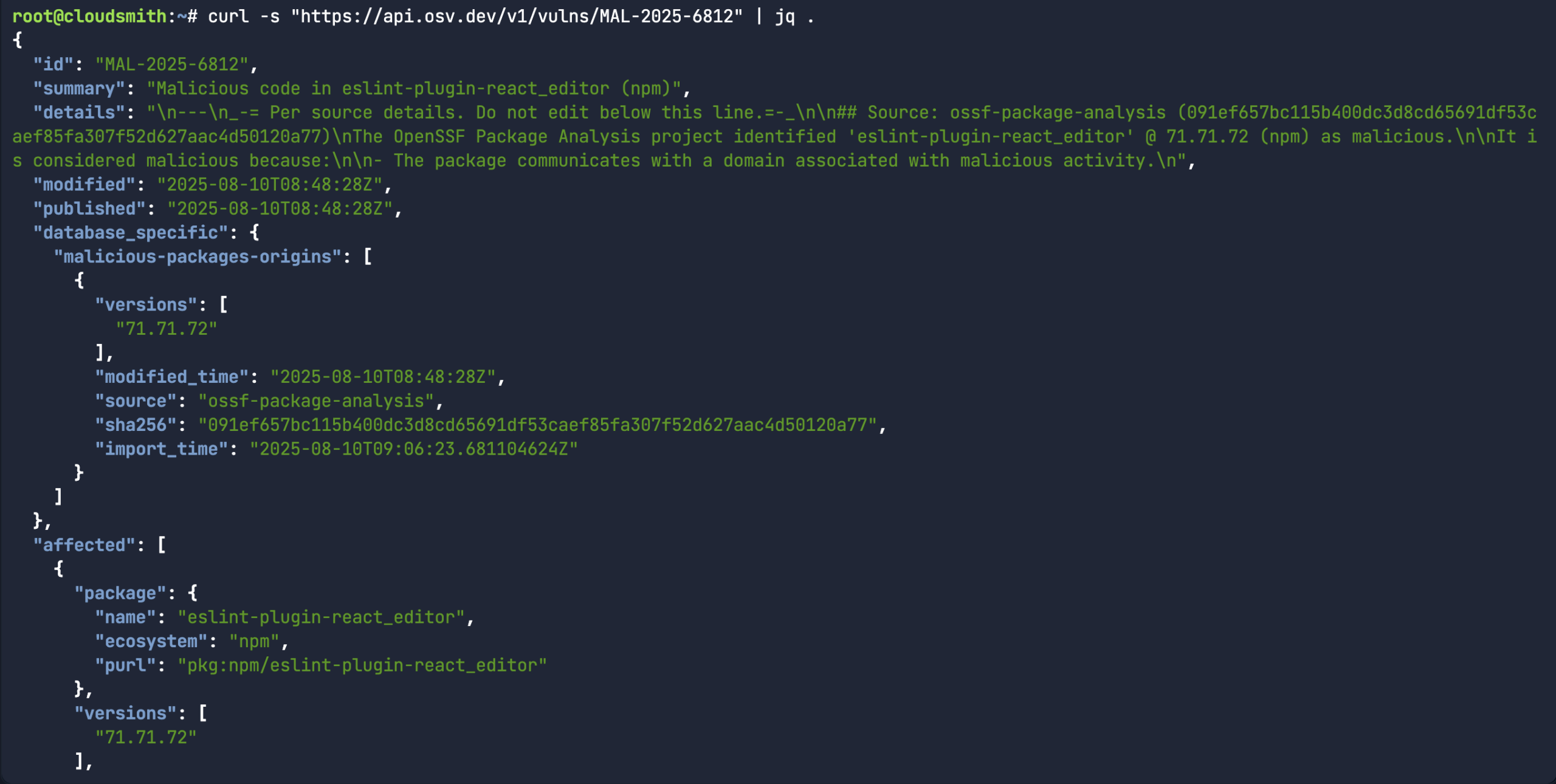 While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie: npm) to see if there’s a malicious package record associated with it.
While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie: npm) to see if there’s a malicious package record associated with it.
curl -s -d '{"package": {"name": "axios", "ecosystem": "npm"}}' "https://api.osv.dev/v1/query" | \ jq '.vulns[] | select(.id | startswith("MAL-"))'
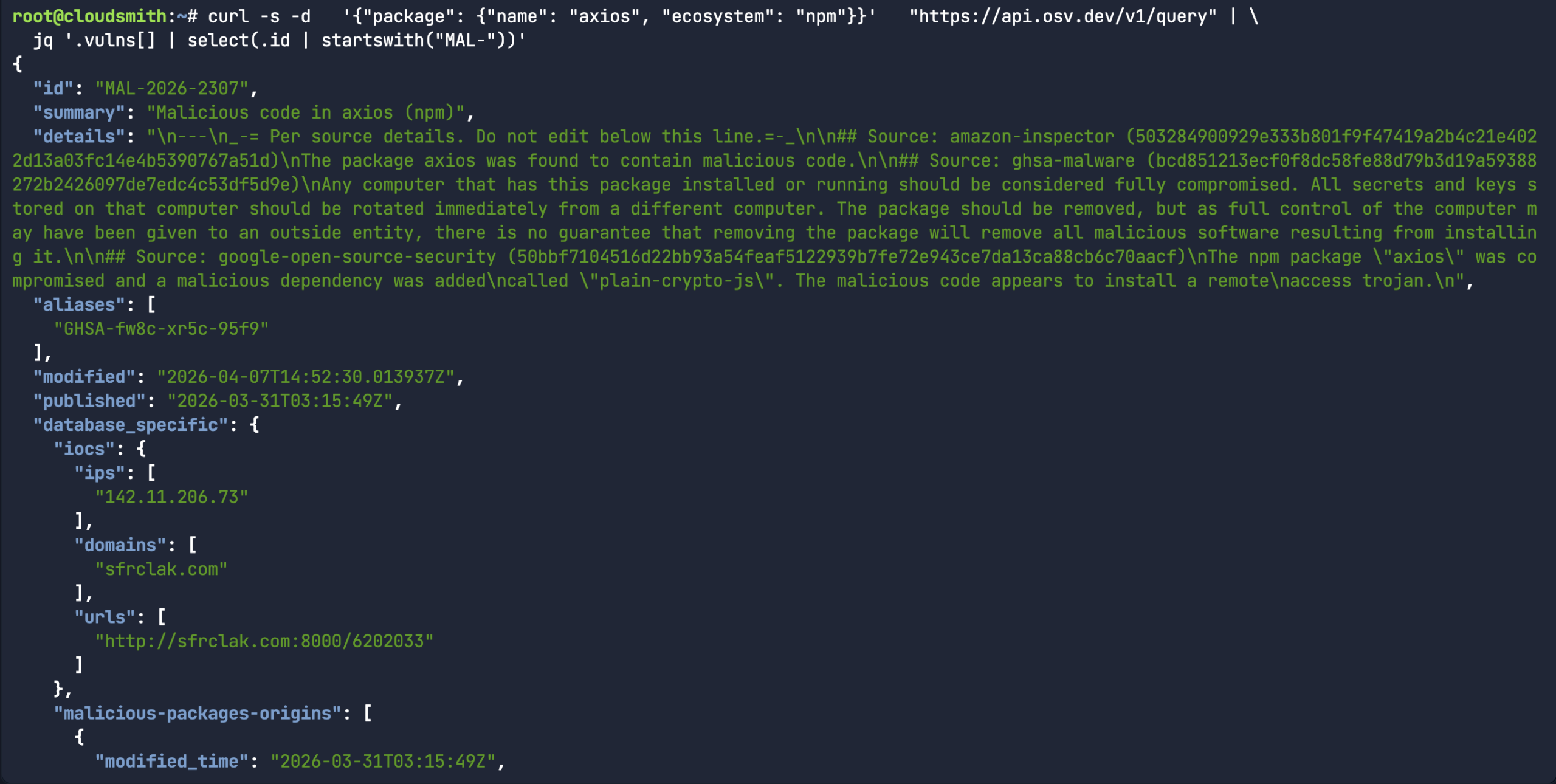 Or in the case of the Axios compromise, there were two different affected versions. Rather than scanning each version separately, you can use the querbybatch endpoint to handle multiple packages, versions and even ecosystems. In the case of MAL-2026-2307, both package versions carry the same malicious package ID.
Or in the case of the Axios compromise, there were two different affected versions. Rather than scanning each version separately, you can use the querbybatch endpoint to handle multiple packages, versions and even ecosystems. In the case of MAL-2026-2307, both package versions carry the same malicious package ID.
curl -s -d \ '{"queries": [ {"version": "1.4.1", "package": {"name": "axios", "ecosystem": "npm"}}, {"version": "0.30.4", "package": {"name": "axios", "ecosystem": "npm"}} ]}' \ "https://api.osv.dev/v1/querybatch" | jq .
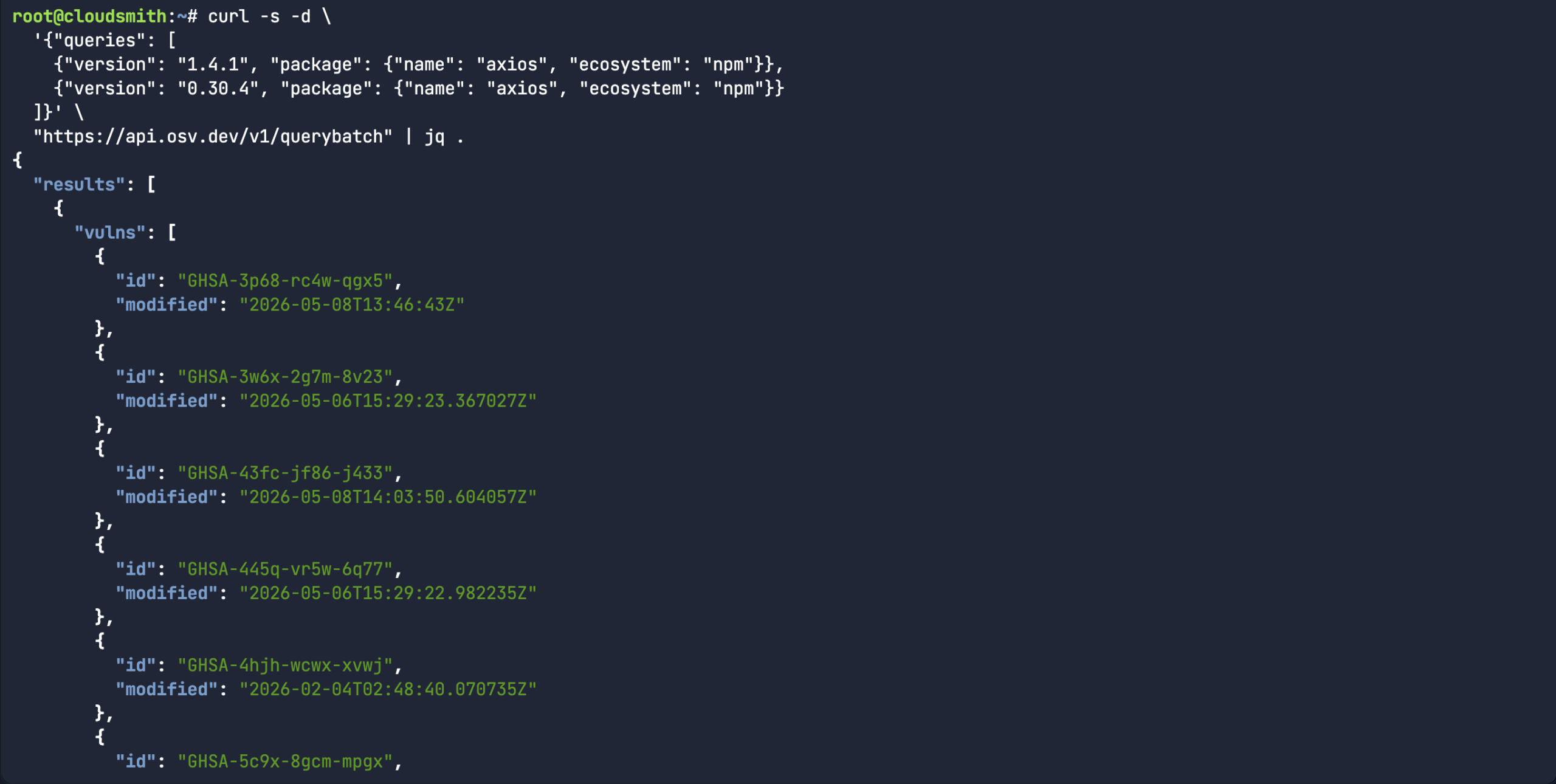
I came up with a simple osv-kubernetes.py scanner. The thought process here is that I could create a simple python-based Kubernetes deployment manifest. This pod has a list of Python packages in the filesystem of the pod, as seen when I run the pip list command.
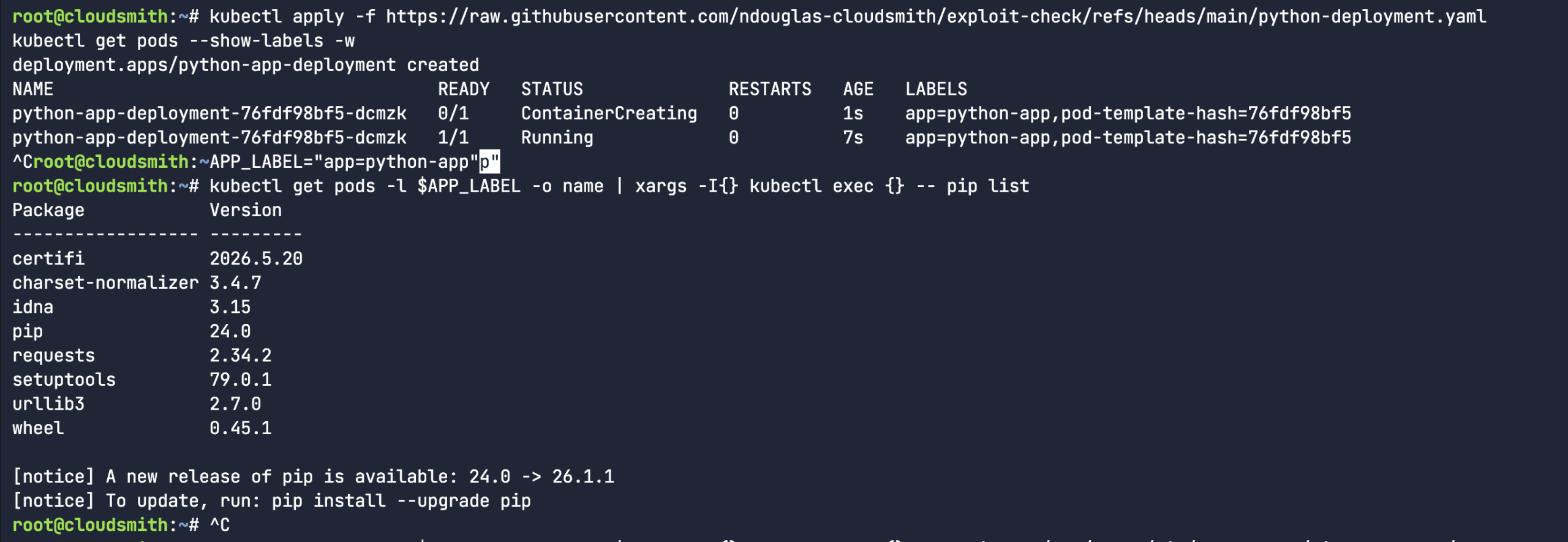 So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom osv-kubernetes scanner script will pick it up.
So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom osv-kubernetes scanner script will pick it up.
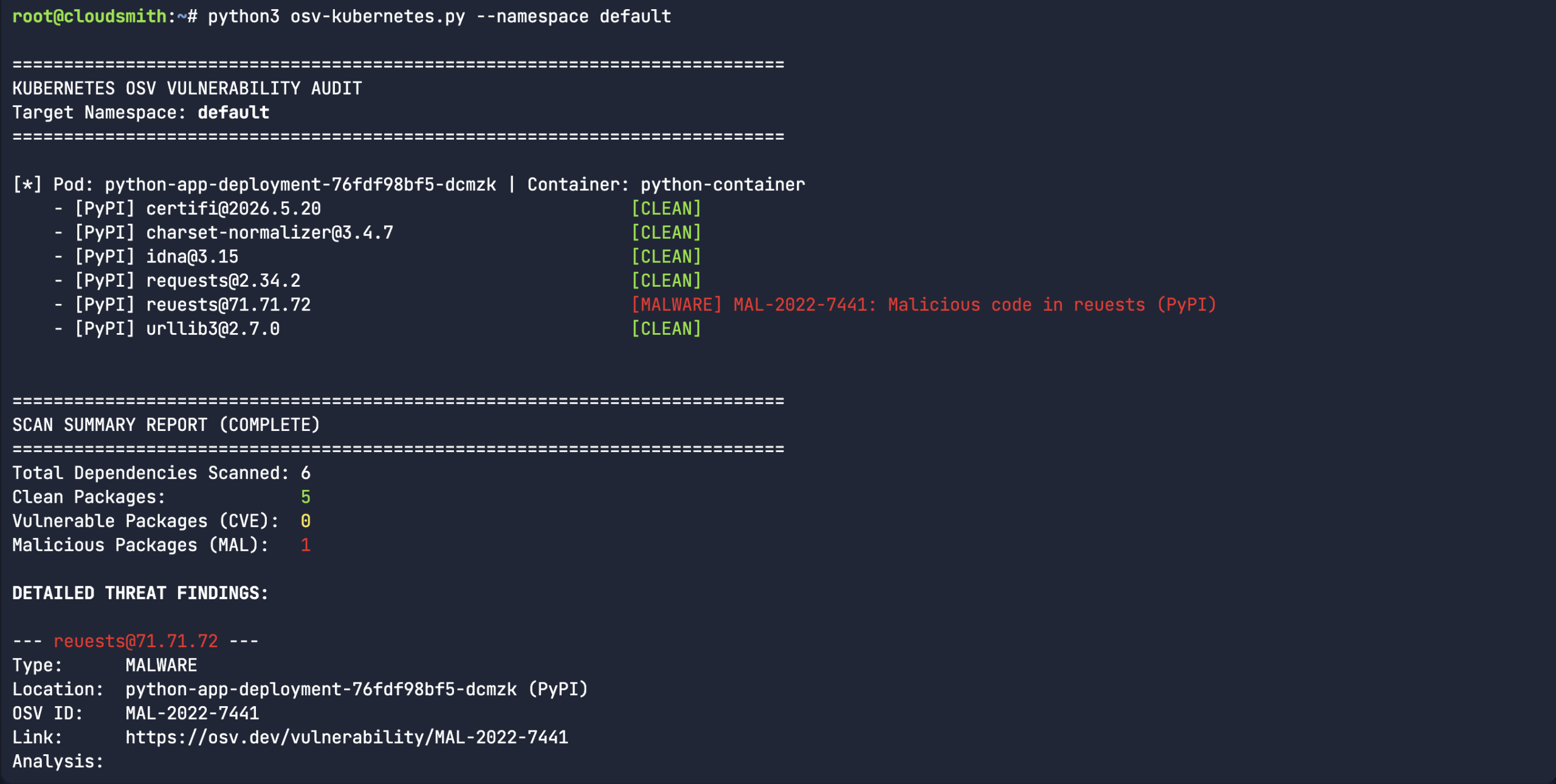 So, we created a fake typosquatted Python package. “Reuests” instead of the legitimate “Requests” library. All versions of the typosquatted Reuests library are tracked under MAL-2022-7441. While this is a simple experiment, it takes us beyond the manual process of scanning each library name and version, and automates it by piping the output of the pip list command into the API query. There are many ways that users can use the OSV API, this was purely an experiment for Kubernetes workloads.
So, we created a fake typosquatted Python package. “Reuests” instead of the legitimate “Requests” library. All versions of the typosquatted Reuests library are tracked under MAL-2022-7441. While this is a simple experiment, it takes us beyond the manual process of scanning each library name and version, and automates it by piping the output of the pip list command into the API query. There are many ways that users can use the OSV API, this was purely an experiment for Kubernetes workloads.
While there are certainly use-cases for building your own custom scanners, like what we did with the Kubernetes pod scanner earlier, I would recommend using the official OSV-Scanner to find existing vulnerabilities and malicious code injection affecting your project’s dependencies. OSV-Scanner provides the officially supported frontend to the OSV database and CLI interface to OSV-Scalibr that connects a project’s list of dependencies with the vulnerabilities that affect them.
In the below scenario, I used syft to create a simple Software Bill of Materials (SBOM) in JSON output based on an existing Python requirements.txt file. As we found out earlier, the OSV API is entirely JSON-structured, so we wouldn’t scan unstructured .txt files. The most common file to scan would be the SBOM or lock files (ie: osv-scanner –lockfile=package-lock.json).
syft packages requirements.txt -o cyclonedx-json=sbom.cdx.json osv-scanner -L sbom.cdx.json
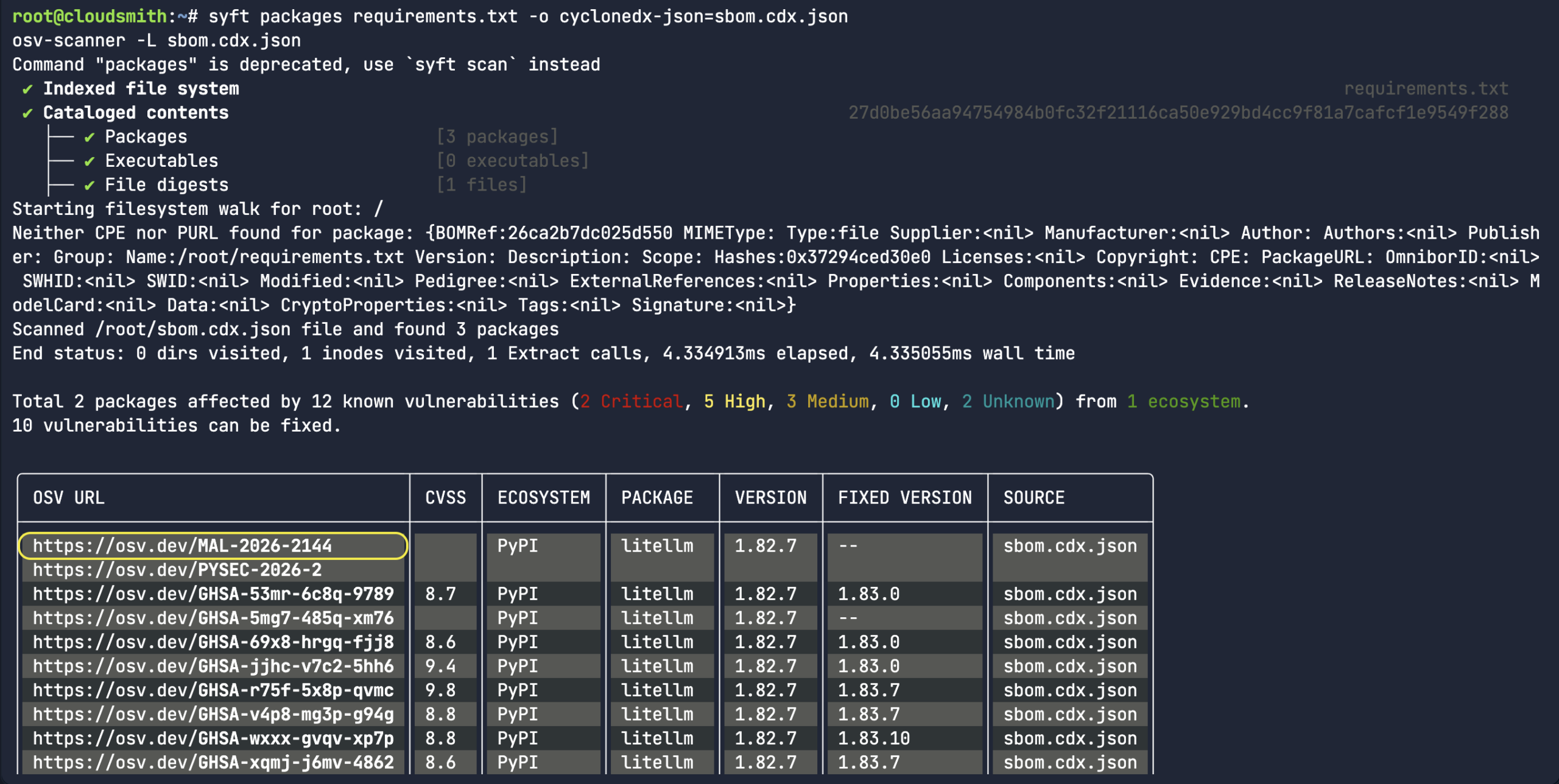
As you can see from the screenshot, the CycloneDX SBOM is successfully sourced. The packages LiteLLM and requests were correctly identified as being from the PyPI ecosystem since the Python requirement.txt file was converted into SBOM. As well as having multiple security advisories related to an upstream compromise, LiteLLM was corrected marked as malicious – MAL-2026-2144.
Again, this process is good and all, but you really need to integrate it into the CI/CD process. The OSV-Scanner Github Action leverages the malicious packages repository and the OSV-Scanner CLI tool to track and notify you of known malicious packages across the existing languages and ecosystems. The most common workflow for Github triggers a scan with each pull request and will only report new instances of malware introduced through the PR. The Github Action compares a scan of the target branch to a scan of the feature branch, and will fail if there are new vulnerabilities or malicious packages introduced through the feature branch. Alternatively, this process can be achieved on Scheduled Scans using a cron job.
I say this a lot, but in light of the recent axios@1.14.1 compromise, please make sure you always commit your npm project with the package-lock.json file. It is the only version-locking enforcement mechanism that exists in npm today. Developers should be using npm ci instead of blindly using npm install on Javascript libraries sourced from npm. The npm ci command will only work if a package-lock.json file exists. These lockfiles can also be easily scanned, as seen with osv-scanner.
Likewise, if you need to update or pull new packages from open source registries like npmjs.com, it’s also worth using the –min-release-age flag (available since npm v11.10.0) to make sure you only install updates, which are at least 3 days old (ie: npm install –min-release-age=3). Most open source malicious packages end up getting classified by OSV.dev within the first 3 days, so configuring a cooldown period is perfect to help prevent consumption of unknown or new variants of malware campaigns.
You can literally hardcode this setting (min-release-age=7) into your .npmrc file. There will always be more malicious actors attacking popular npm and PyPI packages in the future. Thankfully, most will get caught in the first 24 hours, in part due to the fantastic work going on within the OpenSSF Malicious Package packages project. I’m not trying to say that the Javascript (npm) and Python (PyPI) ecosystems are broken by design, but we certainly cannot apply blind trust to the software supply chain.
Get Involved: Help Us Secure the Ecosystem
The strength of the OSV project lies in its community. You can help protect the open source landscape by:
 Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.
Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.


By Helen Woeste
In 2023, DARPA announced a two-year long competition called the Artificial Intelligence Cyber Challenge (AIxCC) with the goal to safeguard open source software used in critical infrastructure throughout America. The intent is to hasten the development of open source AI tooling that can assist developers with finding and fixing bugs in live software with minimal cost. Open source is a drastically underfunded and underresourced form of infrastructure. It therefore presents an exciting, practical target, and opportunity for the research and development of AI in cybersecurity. Additionally, open source’s publicly observable code is ideal for competition and collaboration.
AIxCC was run in collaboration with ARPA-H and supported with contributions from Anthropic, Google, Microsoft, and OpenAI, with additional consulting around open source provided by the Linux Foundation and the Open Source Security Foundation (OpenSSF). This research was developed with funding from the Defense Advanced Research Projects Agency (DARPA). The competition consisted of two rounds, the Semifinal Competition (ASC) and the Final Competition (AFC), where cash prizes from a pot of $30,500,000 were distributed. For the ASC, 42 team submissions were accepted across two tracks; the Open Track and the Small Business Track, which required an additional technical paper submission. The top seven teams moved forward to the AFC which was set up to mimic a real world CI/CD pipeline. The scoring algorithm was also designed to highlight behaviors that would make the competing systems more useful to developers. At the conclusion of AFC, the top three teams were Team Atlanta, Trail of Bits, and Theori.
For the AIxCC competition, real open source projects were selected, and their code was forked and then modified to insert artificial bugs for the Cyber Reasoning Systems (CRS) to discover and fix. However, during the execution of the competition, the CRSs discovered several real potential bugs alongside the artificial ones. This introduced the issue of how to triage and manage resolution of fixes in the projects. OpenSSF engaged third party open source security organization Open Source Technology Improvement Fund (OSTIF) to get involved with the closing out of the bugs identified as a result of the AIxCC competition.
OSTIF selected the team at Ada Logics for their extensive experience working with open source fuzzing, bug verification, and disclosure. With a list of potential bugs identified through the course of the competition, Ada Logics was tasked with securely submitting verified issues, ensuring that anything reported to open source project maintainers was a proven bug. The Ada Logics team was able to reproduce and confirm twenty-seven issues after multiple rounds of testing and continued coordination between AIxCC competitors, collaborators, and contributors. CRS teams, including Team Atlanta, Team Buttercup, Team FuzzingBrain, Team Shellphish, Team Theori, Team 42-b3yond-6ug, and Team Lacrosse, working together with Kudu Dynamics and the OpenSSF, continued to collaborate and meet with OSTIF around the disclosures to ensure total accuracy of the reported issue’s testing and resulting decision around disclosure.
It was of utmost importance that any and all real bugs detected during the competition were verified before alerting the project maintainer to the issue. This is to differentiate how the competition reports issues to projects from the low-quality reports plaguing open source maintainers today. In several cases, CRS-generated patches were submitted alongside bugs, an offering to project maintainers looking to quickly resolve the finding. Additionally, feedback was sourced from the projects around their experience as a target in the competition as well as the disclosure procedure following.
Teams discovered twenty-seven candidate real-world issues during the competition and OSTIF engineers were ultimately able to replicate all of the draft bugs. The affected projects were cURL, shadowsocks-libev, healthcare-data-harmonization, hertzbeat, little-cms, and mongoose. Once identified, the hard work began of fixing those bugs, implementing CRS tooling to perform the second half of its double duty to find and fix security issues.
However, some of the findings did not meet a level of security concern for various reasons. Some issues were fixed by code changes in the projects during the time-period in between the competition and when engineers reproduced them. Others were outside of the threat model of the project and did not meet the criteria needed to incorporate into the project (for example, the Apache Poi project threat model states “Expect any type of Exception when processing documents,” making any exception-based findings non-issues). One issue had actually already been found by OSS-Fuzz, but the project hadn’t fixed it yet.
Ultimately, interesting findings were discovered and fixed by the Cyber Reasoning Systems in this competition, and the systems found a lot of valid issues. Further, some projects had introduced fixes before the bugs were reported. This is likely because the AIxCC teams submitted the fuzzing harnesses to the projects before triage had taken place, which re-discovered the same bugs before triage had completed. One significant lesson learned from this is that cyber reasoning systems may benefit from doing self-triage when discovering potential issues by checking against the project’s documentation and understanding the types of issues that the project accepts as security bugs that need to be addressed.
The AIxCC program was a massive undertaking by dozens of organizations, all working to contribute back to open source security in a meaningful way using novel AI tooling. The competition was mindfully designed and carried out, with attention given towards the open source projects and maintainers, the wide variety of competitors and interests, and the impact of the competition itself on the industry all the way down to the maintainers.
OpenSSF is the home for extended collaboration on these new open source tools through its newly formed Cyber Reasoning Systems Special Interest Group. OSS-CRS and FuzzingBrain, two open source projects that emerged from the competition, are now hosted at OpenSSF in the Linux Foundation. A third tool applied and was accepted to the OpenSSF, and has a few remaining steps before the official transition. The group aims to foster their development and adoption, and to establish best practices that help projects use CRSs effectively and responsibly.
This work is already producing real results. For example, FuzzingBrain has since turned its AI-assisted fuzzing system on the broader open source ecosystem, discovering sixty-two vulnerabilities across twenty-six projects, from CUPS and Apache Avro to Ghidra and OpenLDAP, with forty-three confirmed by maintainers and thirty-six already patched upstream. 42-b3yond-6ug has expanded its CRS to uncover twelve kernel-related vulnerabilities in the Linux kernel and related components, plus ten zero-day vulnerabilities in userspace projects including Eclipse Mosquitto and OpenLDAP. The team is also developing a platform to support more efficient model training and evaluation of models and agents, with a release expected soon. Using OSS-CRS, Team Atlanta discovered twenty-five vulnerabilities across sixteen projects spanning a broad range of software including PHP, U-Boot, memcached, and Apache Ignite 3. Of those, nine have been fixed and eight more have been confirmed with fixes in progress.
The future of AI assisting maintainers in finding and fixing security vulnerabilities is bright. The challenges raised by the AIxCC competition already have solutions being developed in open source, such as LLM-based tools that build threat models by looking at the data-flow of projects, and AI agents that triage findings against threat models and documentation before reporting issues. As these tools all continue to develop, they will harmonize into reliable solutions that maintainers can use to elevate their security with far less effort than today.
Our gratitude to the folks at Ada Logics for triaging the potential bugs and working hard to reproduce the issues so maintainers didn’t have to, OpenSSF for trusting us to bring together all of the stakeholders to work on the issues together, DARPA and ARPA-H for holding the AIxCC competition and sponsoring this work, the teams that built the Cyber Reasoning Systems for the competition, Kudu Dynamics for their support in confirming the findings, and all of the maintainers that worked with us to resolve the issues.
OpenSSF and OSTIF will continue to support this kind of work by serving as human connectors between CRS tools and open source communities. The goal is to help triage and validate vulnerability reports and proposed patches before they reach maintainers, ensuring findings are accurate, actionable, and respectful of maintainers’ time.
Organizing a competition of this scale on behalf of open source maintainers and its end users takes both enormous collaboration and individual effort. Understanding the communities involved, and building lightweight programs that shield maintainers from headaches while strengthening security is the best possible outcome for the ecosystem. It took everyone coming together to make this happen, and ongoing efforts will bring low-cost and low-maintenance tools to everyone that are valuable and make us all safer.
As AI moves forward at breakneck speed, innovative work like this highlights how you can move fast and build things together for a better tomorrow.
 Helen Woeste joined OSTIF in 2023, coming from a decade of work experience in the restaurant and hospitality industries. With a passion (and degree) for writing and governance structures, Woeste quickly transitioned into an operations and communications role in technology.
Helen Woeste joined OSTIF in 2023, coming from a decade of work experience in the restaurant and hospitality industries. With a passion (and degree) for writing and governance structures, Woeste quickly transitioned into an operations and communications role in technology.
The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
Distribution Statement “A” (Approved for Public Release, Distribution Unlimited)


By Devashri Datta, Independent Researcher, Software Supply Chain Security
Third-party notices (TPNs) are documents distributed to users that list open source third-party software components included in the product and key licensing information. Every time you buy a TV or router, you’ve probably seen them. Yet TPNs were never designed for the complexity, scale, and velocity of today’s software ecosystem. TPNs are one of the most widely distributed and yet least understood artifacts in modern software supply chains.
Inside nearly every appliance, firmware image, SaaS platform, and enterprise distribution, the same pattern persists: a long, unstructured PDF is expected to represent the full scope of open source license compliance.
As software systems have scaled, TPNs have quietly become a critical but increasingly fragile pillar. They are now failing technically, operationally, and structurally under the demands of modern development and distribution.
This article examines why TPNs are breaking. It also outlines what the ecosystem must do next based on large-scale analysis of real-world TPN documents and the development of an automated framework for extracting information directly from them. While traditionally viewed as compliance artifacts, Third-Party Notices (TPNs) also represent an underutilized source of security-relevant intelligence. In many real-world scenarios where Software Bills of Materials (SBOMs) are incomplete, unavailable, or restricted, TPNs may provide the only observable evidence of component usage. This positions TPNs as a critical input to software supply chain security workflows, including vulnerability management, third-party risk assessment, and incident response.
Despite advances in Software Bill of Materials (SBOM) formats such as SPDX and CycloneDX, TPNs remain:
SBOMs provide structured visibility into software components, but their completeness depends on the generation methods and the availability of build-time data. In practice, SBOMs may not consistently capture full transitive dependencies or runtime-resolved components. In some cases, additional components and licensing details may appear in downstream artifacts such as third-party notices (TPNs), though these are typically not integrated into SBOM analysis pipelines. SBOM availability also varies across organizations and products and may not always be accessible to end users or external stakeholders due to policy or regulatory interpretation. Regulatory frameworks such as the EU Cyber Resilience Act (CRA) are evolving, and expectations around SBOM scope and disclosure remain subject to interpretation. As a result, relying solely on SBOM data may not provide complete visibility into whether a product contains a specific vulnerable component, depending on SBOM completeness and related artifact availability.
In practice, TPNs often serve as the last mile of compliance visibility, bridging internal software composition and external disclosure.
However, TPNs were never designed to operate at the scale or complexity of today’s supply chains.
While SBOMs and software composition analysis (SCA) tools have improved visibility during development, they assume access to structured or source level data. In contrast, TPNs often represent the only externally available artifact in downstream consumption environments such as embedded systems, firmware, and proprietary SaaS distributions.
This creates a structural blind spot in software supply chain security: security teams are frequently forced to make risk decisions without machine readable component intelligence. As a result, vulnerability exposure, dependency risk, and third-party software usage often remain partially or completely unobservable at the point of consumption.
Most TPNs are distributed as large, heterogeneous PDFs containing:
TPNs often omit component identifiers and lack specific version numbers for components.
PDFs are optimized for display, not structured data. As a result, extracting meaningful compliance information programmatically is extremely difficult.
Current tools such as FOSSology, ScanCode, and ORT are designed to analyze source code or binaries—not TPN documents. Yet in many real-world scenarios, especially audits or vendor reviews, TPNs are the only artifact available.
This creates a fundamental gap: The most widely distributed compliance artifact is the least analyzable.
TPNs are generated through highly variable processes:
As a result, even TPNs from the same organization can vary significantly across releases, introducing inconsistencies, omissions, and misalignment with actual dependencies.
Modern TPNs often span hundreds of pages across multiple license families and components.
Manual review has become increasingly impractical due to:
Compliance teams are effectively being asked to analyze documents at a scale that exceeds human capability.
This work introduces a systematic framework for transforming Third-Party Notices (TPNs) from unstructured compliance artifacts into structured security intelligence inputs. The framework addresses a critical gap in software supply chain security: the absence of machine-readable component visibility in downstream and vendor-distributed environments.
Unlike traditional software composition analysis tools that rely on source code, build artifacts, or SBOMs, this approach operates on TPNs as a primary data source. It enables the extraction, classification, and interpretation of software components and license obligations from highly unstructured documents.
The key contribution of this work is the demonstration that TPNs can be operationalized into actionable security intelligence for:
To address this systemic gap, I developed an automated end-to-end framework that treats TPNs as primary compliance artifacts, rather than secondary documentation.
The approach enables structured extraction and interpretation of license intelligence directly from unstructured documents. While TPNs may lack some information, they still provide valuable signals. For example, even without version identifiers, knowing that a product includes a component can be very valuable (e.g., when asking “which products contain a version of log4j that might be vulnerable to this attack?”).
Using normalization, segmentation, and page-level reconstruction, the system identifies and extracts coherent license blocks even from highly inconsistent documents.
A hybrid approach combining rule-based methods and fuzzy matching maps extracted text into meaningful license categories:
This approach achieves, in my testing:
Each component is evaluated for compliance risk based on obligations such as:
The framework produces:
This demonstrates that meaningful compliance intelligence can be derived even from the most constrained artifact available. This closes a long-standing visibility gap in the software supply chain.
Security Implications of TPN Breakdown
The failure of TPNs is not only a compliance problem—it has direct consequences for software supply chain security. When TPNs are inconsistent, unstructured, or incomplete, they reduce the ability of downstream stakeholders to:
This makes TPN degradation a security visibility problem, not just a documentation inefficiency.
TPN failures are not isolated inefficiencies. They represent a structural weakness in how the global software supply chain communicates compliance.
Addressing this requires coordinated effort across standards, tooling, and ecosystem alignment.
The ecosystem needs formats beyond PDFs, such as:
These would enable structured, interoperable compliance disclosures.
One possible longer-term solution is to embed machine-readable data (such as an SBOM in SPDX format or a TPN in JSON format) within the PDFs, creating a “hybrid PDF”. The PDF format already permits adding internal files (called “attached files”). LibreOffice already supports generating PDFs that embed the source document, allowing people to use their existing process for exchanging display PDF while also including machine-readable data. Tools that can quickly extract those embedded files and complain when they’re not present could speed their deployment. However, while this approach has promise, it doesn’t deal with the current documents, which do not embed this information.
Unsurprisingly, many improvements for handling dependencies could help in processing TPNs, SBOMs, and many other related formats.
It would be better if there was shared reference corpora for license matching. That’s because accurate license detection requires:
This would significantly improve consistency across tools and organizations.
In addition, there should be open APIs for information on licensing. Standard APIs should support:
This would enable interoperability between vendors, auditors, and regulators.
Today, SBOMs and TPNs exist in disconnected workflows. Yet in many cases, TPNs provide the only information available about product components.
A unified pipeline would:
Prior efforts across the software supply chain ecosystem have focused on improving license detection and SBOM generation during development and build phases. However, these approaches often assume access to source code or structured metadata, leaving a visibility gap when Third‑Party Notices (TPNs) are the only available compliance artifact.
Related work on automating TPN analysis demonstrates how unstructured compliance documents can be transformed into machine‑readable license intelligence suitable for governance and audit workflows. Supporting datasets for compliance governance and SBOM alignment are described in:
Datta, D., **TPN Compliance Dataset for Software Supply Chain Governance**, Zenodo, 2025.
https://doi.org/10.5281/zenodo.19152619
Framework:
https://doi.org/10.5281/zenodo.19099831
The proposed framework reframes TPNs as an input layer in modern software supply chain security workflows. Rather than treating TPNs as static compliance documentation, they can be operationalized into structured security intelligence pipelines.
The extracted data can be integrated into:
This positions TPN analysis as a bridge between compliance documentation and operational security decision-making.
Third-party notices (TPNs) were originally designed as simple attribution mechanisms and ways to declare licenses to recipients (as required by many licenses). Today, they are expected to support audits, transparency, regulatory compliance, and supply chain security.
But they are still delivered as static documents that do not scale.
TPNs are not failing because organizations lack intent; they are failing because the ecosystem has outgrown the tools and formats upon which it relies.
If we want a more transparent, auditable, and trustworthy software supply chain, TPNs must evolve into structured, machine-readable, and interoperable artifacts.
The next phase of open source security will not be defined solely by SBOMs or scanning tools, but by how effectively we solve the last mile of compliance visibility.
Fixing TPNs is an important step toward a more reliable and verifiable software ecosystem.
Acknowledgments
The author acknowledges David A. Wheeler and Sally Cooper for their insightful feedback and helpful discussions during the development of this work.
The open source implementation of the prototype described in this post, including parsing logic, license-classification rules, and the interactive dashboard, is available on GitHub for anyone interested in exploring or extending the approach:
https://github.com/devashridatta-dotcom/tpn-automation
Community feedback and contributions are welcome.
 Devashri Datta is an AI & Software Supply Chain Security Researcher. Security researcher and enterprise security architect focused on software supply chain security, DevSecOps automation, and security governance at scale. Research areas include SBOM governance, vulnerability intelligence (VEX), Third-Party Notice (TPN) analysis, AI-assisted risk modeling, and security exception management in cloud-native environments under compliance frameworks such as SOC 2, ISO 27001, and FedRAMP.
Devashri Datta is an AI & Software Supply Chain Security Researcher. Security researcher and enterprise security architect focused on software supply chain security, DevSecOps automation, and security governance at scale. Research areas include SBOM governance, vulnerability intelligence (VEX), Third-Party Notice (TPN) analysis, AI-assisted risk modeling, and security exception management in cloud-native environments under compliance frameworks such as SOC 2, ISO 27001, and FedRAMP.

By Jonas Rosland
Security teams in 2026 have no shortage of data, alerts, or findings. In 2025 alone, 48,185 Common Vulnerabilities and Exposures (CVEs) were published, a 20.6% increase over 2024’s already record-breaking total of 39,962. That works out to roughly 130 new vulnerabilities disclosed every single day, and for seven consecutive years, the annual count has hit a new record high.
The drivers are structural: the explosive growth of open source software, the complexity of transitive dependencies hidden deep in software supply chains, and an expanding CVE ecosystem that now encompasses nearly twice as many reporting organizations as it did five years ago. With 97% of commercial applications containing open source components, inherited risk has become a routine part of working with modern software.
While only 2% of all discovered vulnerabilities are ever exploited in the wild, of that small fraction, nearly 29% were exploited on or before the day their CVE was published. Attackers are selective, but once they identify a target, the window for defenders is very narrow. The window between vulnerability disclosure and confirmed exploitation is also shrinking. Whereas that timeline was over a year in 2020, it’s now shrunk to just hours.
The old model of scanning everything, triaging by Common Vulnerability Scoring System (CVSS) score, and working through a queue simply cannot keep pace with this reality. Something has to change.
The vast majority of what your vulnerability scanner finds will never actually be used against you. That means the core challenge facing security teams isn’t patching speed, but knowing where to focus. When a scanner returns thousands of findings ranked only by CVSS score, what looks like a workload problem is really a prioritization problem. Critical vulnerabilities in libraries that aren’t loaded at runtime, or in containers that haven’t run in months, crowd out the findings that genuinely matter, such as exploitable vulnerabilities in running, exposed workloads. The result is alert fatigue, missed priorities, and growing friction between security and development teams.
The OpenSSF Best Practices criteria reflect this directly. At the “Passing” level, projects must not contain unpatched vulnerabilities of medium or higher severity that have been known publicly for more than 60 days, and critical vulnerabilities should be fixed rapidly after they are reported. The emphasis here isn’t on the volume of findings processed, but on the speed and accuracy with which the most dangerous vulnerabilities are addressed, a distinction that gets lost when teams are buried in undifferentiated backlogs.
Static analysis is non-negotiable. The OpenSSF Best Practices criteria require it at the “Passing” level, and at “Silver,” projects must use tools that look for real vulnerabilities in code, not just style issues. Integrated into CI/CD pipelines, static analysis catches bugs early when they are cheapest to fix, and it remains a solid foundation of any security program. However, alone, it’s not enough.
The limitation is that static analysis sees everything, regardless of whether it matters in practice. It cannot tell you whether a vulnerable library is actually loaded in a running container, or whether that container ever receives external traffic. A CVSS 9.8 score looks identical whether the package is called thousands of times a day in a critical service or has never once been invoked in production. Runtime security fills that gap by observing what is actually executing in production. By tracking which processes are running, which packages are loaded, and which connections are being made, security teams gain much more precise intelligence about where risk actually lives.
Only 15% of critical and high-severity vulnerabilities with an available fix are in packages actually loaded at runtime. By isolating that subset, teams can reduce the scope of what needs immediate attention to a small fraction of their total backlog, in some cases by over 95%. That’s the practical difference between a list that overwhelms a development team and one they can actually act on. Static analysis provides breadth by catching everything possible during development, while runtime intelligence adds depth by showing what genuinely matters in production. Together, they give teams the context to make better decisions.
Runtime data also changes how security teams and developers talk to each other. Telling a developer “this CVE is rated 8.1” lands very differently than “this vulnerability is in a package actively loaded in your production authentication service.” The second statement connects a finding to a tangible business risk, and that context helps developers understand urgency in a way that a severity score on its own rarely does.
When security teams can bring developers a short, contextualized list of what needs attention and why, the conversation tends to shift from friction to collaboration. The OpenSSF Best Practices framework supports this kind of working relationship structurally, requiring documented vulnerability response processes, response times under 14 days, and release notes that explicitly identify runtime vulnerabilities fixed in each release. These aren’t bureaucratic requirements, but the scaffolding for the kind of consistent, trust-based communication that makes vulnerability management work in practice.
Neither team can do this work alone. Security engineers don’t always know which code paths are business-critical, and developers don’t always have visibility into what their software looks like from an attacker’s perspective. Runtime data helps bridge that gap by giving both sides a shared, evidence-based view of where the real risk lives.
Prioritization manages the vulnerability problem today, but reducing the attack surface is how you make the problem smaller tomorrow. Runtime intelligence supports two practical strategies that static scanning alone cannot.
The OpenSSF Best Practices criteria encourage minimizing the attack surface throughout, and the logic applies equally in production environments. The best vulnerability is the one that doesn’t exist because the vulnerable component was never there, and the next best outcome is knowing quickly when something unexpected is happening around the ones that remain.
The 2025 numbers make one thing very clear: the volume of vulnerabilities isn’t going down, and teams that try to treat every finding with equal urgency will continue to struggle. The more practical path is to use static analysis and runtime intelligence together, letting each do what it does best, and to use that shared context to build better working relationships between security and development teams. Finding the right vulnerabilities to fix, explaining why they matter, and making it straightforward for developers to act on them is where the real progress happens.
 Jonas Rosland is Director of Open Source at Sysdig, where he works on cloud-native security and open source strategy. Sysdig supports open source security projects, including Falco, a CNCF graduated project for runtime threat detection.
Jonas Rosland is Director of Open Source at Sysdig, where he works on cloud-native security and open source strategy. Sysdig supports open source security projects, including Falco, a CNCF graduated project for runtime threat detection.

By Tracy Ragan
Over the past decade, the IT community has made significant progress in improving pre-deployment vulnerability detection. Static analysis, Software Composition Analysis (SCA), container scanning, and dependency analysis are now standard components of modern CI/CD pipelines. These tools help developers identify vulnerable libraries and insecure code before software is released.
However, security does not end at build time.
Every successful software attack ultimately exploits a vulnerability that exists in a running system. Attackers can and do target code repositories, CI pipelines, and developer environments; these supply chain attacks are serious threats. But vulnerabilities running in live production systems are among the most dangerous because, once exploited, they can directly lead to persistent backdoors, system compromise, lateral movement, and data breaches.
This reality exposes an important gap in how organizations manage vulnerabilities today. While significant attention is placed on detecting vulnerabilities before deployment, far fewer organizations have effective mechanisms for identifying newly disclosed CVEs that affect software already running in production.
Across the industry, most development teams today run some form of pre-deployment vulnerability scanning, yet relatively few maintain continuous visibility into vulnerabilities impacting deployed software after release. This imbalance creates a dangerous blind spot: the systems organizations rely on every day may become vulnerable long after the code has passed through security checks.
As the volume of vulnerability disclosures continues to increase, the industry must rethink how post-deployment vulnerabilities are detected and remediated.
Modern software systems depend heavily on open source components. A typical application may include hundreds, or even thousands, of transitive dependencies. While security scanning tools help identify vulnerabilities during development, they cannot predict vulnerabilities that have not yet been disclosed.
New CVEs are published daily across open source ecosystems. When a vulnerability is disclosed affecting a widely used package, thousands of deployed applications may suddenly become vulnerable, even if those applications passed every security check during their build process.
This creates a persistent challenge: software that was secure at release can become vulnerable later without any code changes.
In many organizations, the detection of these vulnerabilities relies on periodic rescanning of artifacts or manual monitoring of vulnerability feeds. These approaches introduce delays between vulnerability disclosure and detection, extending the window of exposure for deployed systems.
Because attackers actively monitor vulnerability disclosures and quickly develop exploits, this detection gap creates significant operational risk.
Organizations today use several methods to identify vulnerabilities affecting deployed software. While each approach has value, they are often costly and introduce operational complexity.
One common strategy involves rescanning previously built artifacts or container images stored in registries. Security teams periodically run vulnerability scanners against these artifacts to identify newly disclosed CVEs. Although this approach can detect vulnerabilities that were unknown at build time, the process cannot identify where the containers are running across system assets.
Another approach relies on host-based security agents or runtime inspection tools deployed on production infrastructure. These tools identify vulnerable libraries by inspecting installed packages or monitoring application behavior. In practice, these solutions are most commonly implemented in large enterprise environments where dedicated operations and security teams can manage the operational complexity. They often require significant infrastructure integration, deployment planning, and ongoing maintenance.
Agent-based approaches also struggle to support edge environments, embedded systems, air-gapped deployments, satellites, or high-performance computing clusters, where installing additional runtime software may not be feasible or permitted. Even in traditional cloud environments, deploying and maintaining agents across thousands of systems can be a substantial operational lift.
This complexity stands in sharp contrast to pre-deployment scanning tools, which can often be installed in CI/CD pipelines in just minutes. Integrating a software composition analysis scanner into a build pipeline typically requires only a small configuration change or plugin installation. Because these tools are easy to adopt and operate earlier in the development lifecycle, they have seen widespread adoption across organizations of all sizes.
Post-deployment solutions, by comparison, often require significantly more effort to deploy and maintain. As a result, far fewer organizations implement comprehensive post-deployment vulnerability monitoring. While most development teams today run some form of pre-deployment vulnerability scanning, relatively few maintain continuous visibility into vulnerabilities impacting software already running in production. This leaves a critical visibility gap in the environments where vulnerabilities are ultimately exploited: live operational systems.
A more efficient model for detecting post-deployment vulnerabilities already exists but is often underutilized.
Software Bill of Materials (SBOMs) provide a detailed inventory of the components included in a software release. When generated during the build process using standardized formats such as SPDX or CycloneDX, SBOMs capture critical metadata, including component names, versions, dependency relationships, and identifiers such as Package URLs.
SBOM adoption has accelerated in recent years due in part to initiatives such as Executive Order 14028 and ongoing work across the open source ecosystem. Organizations increasingly generate SBOMs as part of their software supply chain transparency efforts.
Yet in many environments, SBOMs are treated primarily as compliance documentation rather than operational security tools. Instead of being archived after release, SBOMs can serve as persistent inventories of the components running in deployed software systems.
When SBOMs are available and associated with deployed releases, detecting newly disclosed vulnerabilities becomes significantly simpler.
Vulnerability intelligence feeds, such as the OSV.dev database, the National Vulnerability Database (NVD), and other vendor advisories, identify the packages and versions affected by each CVE. By correlating this vulnerability information with stored SBOMs and release metadata, organizations can quickly determine whether a deployed asset includes an affected component.
Because the SBOM already describes the complete dependency graph, there is no need to reanalyze artifacts or rescan source code. Detection becomes a metadata correlation problem rather than a compute-intensive scanning process.
This model enables organizations to continuously monitor deployed software environments and identify newly disclosed vulnerabilities almost immediately after they are published.
To operationalize this approach at scale, organizations need systems capable of continuously tracking the relationship between software releases, deployed environments, and their associated SBOMs. One emerging concept is the creation of a software digital twin, a continuously updated model that represents the software components running across operational systems.
A digital twin maintains the relationship between deployed endpoints and the SBOMs that describe the software they run. By synchronizing these SBOM inventories with vulnerability intelligence sources such as OSV.dev or the NVD at regular intervals, organizations can automatically detect when newly disclosed CVEs impact running systems.
Rather than waiting for scheduled scans or relying on agents installed on production infrastructure, this model enables continuous vulnerability awareness through metadata synchronization.
Once an affected component is identified, remediation workflows can also be automated. Modern development platforms already rely on dependency manifests such as pom.xml, package.json, requirements.txt, or container Dockerfiles. By automatically updating these dependency files and generating pull requests with patched versions, organizations can rapidly move fixes back through their CI/CD pipelines.
This type of automation has the potential to reduce vulnerability remediation times from months to days, dramatically shrinking the window of exposure. And, it is easy to scale, giving developers more control and visibility into the production threat landscape.
Efforts across the Open Source Security Foundation (OpenSSF) ecosystem have helped establish the foundational infrastructure needed for this approach.
The OSV.dev vulnerability database provides high-quality vulnerability data tailored to open source ecosystems. Standards such as SPDX and CycloneDX enable consistent representation of SBOM data across tools and platforms. Projects like OpenVEX provide mechanisms for communicating vulnerability exploitability context, helping organizations determine which vulnerabilities require immediate attention.
Together, these initiatives create the building blocks for a more efficient and scalable vulnerability management model, one that relies on accurate software inventories and continuous vulnerability intelligence rather than repeated artifact scanning.
Pre-deployment security scanning will continue to play an important role in software development. Identifying vulnerabilities early in the development lifecycle reduces risk and improves software quality.
But the security landscape is evolving. As software ecosystems grow more complex and vulnerability disclosures increase, organizations must also strengthen their ability to detect vulnerabilities that appear after software has already been deployed.
Rethinking post-deployment vulnerability detection means shifting away from repeated artifact scanning and toward continuous monitoring of software composition.
SBOMs provide the foundation for this shift. When combined with digital twin models that track deployed software, continuous synchronization with vulnerability databases, and automated dependency remediation, organizations can dramatically improve their ability to defend operational systems.
One thing is certain: attackers ultimately focus on exploiting vulnerabilities running in live systems. Gaining clear visibility into the attack surface, understanding exactly what OSS packages are deployed, where they are running, and how quickly they can be remediated, is essential to securing live systems from cloud-native to the edge.
 Tracy Ragan is the Founder and Chief Executive Officer of DeployHub and a recognized authority in secure software delivery and software supply chain defense. She has served on the Governing Boards of the Open Source Security Foundation (OpenSSF) and currently serves as a strategic advisor to the Continuous Delivery Foundation (CDF) Governing Board. She also sits on both the CDF and OpenSSF Technology Advisory Committees. In these roles, she helps shape industry standards and pragmatic guidance for securing the software supply chain and advancing DevOps pipelines to enable safer, more effective use of open-source ecosystems at scale.
Tracy Ragan is the Founder and Chief Executive Officer of DeployHub and a recognized authority in secure software delivery and software supply chain defense. She has served on the Governing Boards of the Open Source Security Foundation (OpenSSF) and currently serves as a strategic advisor to the Continuous Delivery Foundation (CDF) Governing Board. She also sits on both the CDF and OpenSSF Technology Advisory Committees. In these roles, she helps shape industry standards and pragmatic guidance for securing the software supply chain and advancing DevOps pipelines to enable safer, more effective use of open-source ecosystems at scale.
With more than 25 years of experience across software engineering, DevOps, and secure delivery pipelines, Tracy has built a career at the intersection of automation, security, and operational reality. Her work is focused on closing one of the industry’s most critical gaps: detecting and remediating high-risk vulnerabilities running in live, deployed systems, across cloud-native, edge, embedded, and HPC environments.
Tracy’s expertise is grounded in decades of hands-on leadership. She is the Co-Founder and former COO of OpenMake Software, where she pioneered agile build automation and led the development of OpenMake Meister, a build orchestration platform adopted by hundreds of enterprise teams and generating over $60M in partner revenue. That experience directly informs her current mission: eliminating security blind spots that persist long after software is released.