Summary
In this episode of Big Thoughts, Open Sources, host CRob sits down with Jamie Thomas, IBM Enterprise Security Executive and OpenSSF Governing Board Member (former Chair!), to tackle the vital shifting dynamics of enterprise open source engagement. From IBM’s historical “billion-dollar bet” on Linux to modern supply chain wake-up calls like SolarWinds and Log4j, Jamie pulls back the curtain on what it truly means to move from accidental consumption to intentional stewardship. Tune in to discover how active participation in neutral foundations like the OpenSSF acts as a fast track for engineering career trajectories, why soft skills like “the art of influence” are critical for upstream collaboration, and how organizations can protect their crown jewels while implementing a powerful “give-back strategy.”
Conversation Highlights
00:00 – Intro Music + Promo Clip
00:21 – Introduction & Welcoming Luminary Jamie Thomas
01:32 – Wearing the Enterprise Security Hat at IBM
02:10 – Supply Chain Wake-up Calls: From SolarWinds to Log4j
03:14 – Unlocking Open Ecosystems: IBM’s Early History with Java and Linux
05:21 – Mainframe Debates and Portability: The Evolution of Open Source Adoption
06:24 – The Red Hat Acquisition and Monetizing the Developer Ecosystem
08:20 – The Myth of “Free” Software: Securing Regulated Enterprise Deployment
10:15 – Why a Seat at the Table Matters: The Value of Neutral Foundations
11:29 – The Art of Influence: Upstream Contributions as a Career Catalyst
13:50 – Moving Innovation from Open Source Kernels to Commercial Value
16:12 – Storming, Norming, and Conversation: Lessons from the Kubernetes Era
17:38 – Pitching Upstream Time: Helping Developers Sell Open Source to Management
19:30 – Beyond Code: Bringing Domain Expertise and Soft Skills Upstream
21:40 – Conquering the Chasm: Automating CI/CD Pipelines and Testing at Scale
22:56 – Consuming with Intent: Active Stewardship and the OpenSSF Scorecard
25:21 – Rapid Fire Round: Mainframes, AI-Generated Code, and Star Trek nostalgia
27:53 – Call to Action: Crafting Your Organization’s “Give-Back Strategy”
Transcript
Music & Intro/Promo clip (00:00)
If you’re a direct consumer of open source, do it with intent. And intent means that you’re responsible for what that means to your organization, both from a productivity perspective, but also from a security perspective and what you can expect from an investment point as well. You have to be an active steward in the maintenance of your open source strategy, just like you would have to be a steward of the maintenance of your own home.
CRob (00:26)
Welcome, welcome, welcome to Big Thoughts Open Sources. My name’s CRob. I’m your host today. This is a special video series where we’re talking to some of the leaders within open source. And today we have an amazing treat. We have Jamie Thomas from IBM. It’s a little company you might’ve heard of. And she’s here today to kind of talk about maintaining a career and influence within open source. Welcome, Jamie.
Jamie Thomas (00:54)
Thanks, Crob. Thanks for having me.
CRob (00:56)
I think we’re going to have a pretty amazing conversation today. For those of you that might be unfamiliar with kind of the luminaries that exist within our little slice of open source security heaven, Jamie has been alongtime contributor and member to the OpenSSF, predominantly through influence through our Governing Board. You actually were our Governing Board Chair for a period of time. So for those that may be unfamiliar with you, could you maybe talk about what your current role is at IBM and kind of what you do within the OpenSSF?
Jamie Thomas (01:32)
Absolutely, and thanks for having me again. I think this is a really interesting topic. At IBM, I have a couple of hats, but the main hat that is important to this discussion today is IBM Enterprise Security Executive. And I’m therefore responsible for the protection of the IBM company. It includes our CISO office, our Cybersecurity Operations, as well as our Product Security, which has to span a number of our units, including our software, hardware, our consulting unit. So it’s an interesting job.
CRob (02:05)
Really big job.
Jamie Thomas (02:10)
Yeah, and you know, as you know, CRob, I got involved in OpenSSF from the very beginning of the Governing Board. And I remember when I got involved in enterprise security, someone told me, by the way, it’s all quiet, there’s not much going on right now. And, and the first thing that I recall happening not long after that was SolarWinds, which was one of the first interesting supply chain attacks. And then of course, we had Log4j, which is another whole realm of fun.
But certainly I felt that joining OpenSSF has been important for us, the IBM company, to stay abreast of what’s happening in the industry and to be a participant in this open source security realm. It continues to be an ever changing landscape.
CRob (02:53)
Absolutely, a blink and it totally changes. It’s a pretty wild space we get to live in. Thinking back through your career here, was there a moment or something that really sparked your interest that kind of drew you towards more open source perspectives, participation?
Jamie Thomas (03:14)
Yeah, yeah, absolutely. I mean, when I started IBM, I did start as a programmer in the software organization. And at that time, of course, we worked on, like all of the industry, probably at that time, closed source systems. But at some point in IBM, we got very involved in something called Java. As part of…
CRob (03:32)
I’ve heard of it.
Jamie Thomas (03:34)
Haha, yeah you’ve heard of Java…As part of Java, we wanted to engender an open ecosystem around the Java programming model.
And to that end, we realize we’re not going to attract developers at scale without a different approach.
And so we made some concerted decisions at that time. One was that we would invest in Linux. There was something called Linux at that time. And we made a decision to put into the corporation Linux Technology Center to invest in Linux, be open source contributors to the Linux operating system. And the other big decision we made is that we would outsource some of our Java development tooling to something called the Eclipse Foundation.
CRob (04:16.691)
Mm-hmm, oh yeah.
Jamie Thomas (04:17)
So it seems like, you know, tribal knowledge at this point, but to say the least, embarking on some of these endeavors was quite unique for the IBM company at the time. And getting people to understand their role within an open source community as opposed to what we had always traditionally done in terms of how we provided software to clients was very, different.
And I had the pleasure of being involved in both the Java effort and the Eclipse Foundation effort through our Rational Software Division. And at that time, I actually owned all of the folks that were contributing to Eclipse and got to see that evolve for a period of time. You know, that was very, very fascinating times for IBM and also, I think, important for the evolution of open source that we have today.
CRob (05:09)
Well, in thinking further downstream, the folks, the organizations that would be your customers, Java was probably one of their, also their entry points into the open source ecosystem.
Jamie Thomas (05:21)
Mm-hmm. It absolutely was because you found through the eyes of lot of our enterprise clients as they adopted Java, they were naturally then adopting Eclipse. And over a period of time, they certainly became very strong supporters of the Linux operating system. And in fact, I remember one of the first meetings we had where we actually were in a room with all these clients and there became this huge argument, this huge argument about whether we should put on the IBM mainframe.
And you can imagine, there were a variety of opinions in that room. But what made sense, if you thought about it, is that Linux would give us portability. And if folks developed on Linux, of course, then ultimately portability to different hardware platforms, of course, would be gained through Linux. And that’s exactly what did happen.
But at that time it was a very, very novel concept that we should embrace this new operating system. And so it was fun, fun stories.
CRob (06:24)
Speaking of fun stories, several years back, IBM made the air quotes, billion dollar bet on Linux and kind of looking back at kind of IBM’s initial involvement with the ecosystem and Java, and then through the acquisition of Red Hat, kind of thinking about what was the most difficult part kind of moving these massive enterprises towards an open source first mindset.
Jamie Thomas (06:53)
Well, I think that by the time we made that multi billion dollar bet on something called Red Hat, our perspective of open source had matured quite a bit. We had then already discovered and learned that we did.
CRob (07:02)
Mm-hmm.
Jamie Thomas (07:03)
We had then already discovered and learned that we did. monetize quite well the Java ecosystem and part and parcel to what we did around Eclipse and Linux. We’d also adopted scale Linux on our platforms on both the Z platform in particular and Power and also we were stewards of Linux on x86 for our clients. So we had a different perspective. And I think at the time we acquired Red Hat though, we did understand the needle had moved quite a bit on the developer ecosystem. In that period of time since we had first started some of these efforts and that Red Hat would enable us to have a bigger stake in the open source community as well as the ability to reach developers at scale.
And that was part of the motivation for the acquisition and I think that it definitely served us well. I believe that what Red Hat does, curated open source is something that’s really important for the industry to have a competent enterprise level open source provider, but that once again,has their finger in the pie around the open source community because that’s where everything happens. It happens in the community and then it has to bubble upstream and be effective for the enterprises that are consuming it.
CRob (08:20)
I know we’ve talked many times that you get the opportunity to talk to a lot of business and cyber leaders at firms that you partner with. Kind of when you’re providing advice and counsel to these leaders, how do you kind of reassure them that they’re not going to be contributing to open source isn’t going to be giving away their secret sauce or their crown jewels? How do you encourage them in engaging more and more effectively with open source?
Jamie Thomas (08:50)
Well, I think there’s two different perspectives. And when you talk when I talked to a lot of the client organizations, I think they have pretty much accepted that open source is a valuable asset to them. What they’re then looking for is who can help me ensure that I’ll have operational fidelity, security around this open source. And that’s when they then start to say, should I have a trusted vendor to work with on that point? Or am I going to consume it directly?
And, and certainly, Isee that early on in the acquisition of technology that many enterprises just take the open source and try it out. I mean, that’s one of the benefits, right? You can try it out. You can test drive it, you can decide if it works for you. But then normally, if you go into enterprise deployment, you do want someone that’s going to be there. In many cases I’m going to provide the care and feeding for you, particularly if you’re in a regulated industry. And of course, we deal with a lot of regulated firms and in our environment.
I also also make sure that I remind everybody involved, including ourselves and our ecosystem, that open source is really not totally free. I mean, it’s something that we all have an obligation to support. So if we’re consuming it, we need to understand what that means and we need to be stewards of ensuring that the open source communities are successful going forward.
CRob (10:15)
That’s an interesting point that leads me to my next question. How vital is it for enterprises to participate in neutral bodies like the OpenSSF or Eclipse or CNCF, rather than just trying to take all these amazing tools and kind of assemble it themselves, how does that neutral collaboration help them?
Jamie Thomas (10:36)
Well, I think it’s very important for you to, as an organization to have a seat at the table, if you will, realizing that in today’s world, you know, software doesn’t stay in the boundaries of one company. I mean, there’s an extensive ecosystem out there, we’re all somewhat interconnected. And if you’re at the table, you have an ability to influence the direction of a lot of these projects, you had the ability to contribute uniquely, but most importantly, to make sure that the projects understand your unique point of view. Certainly there’s a point of view of technology organizations like IBM. There’s a there’s a the the point of view of the startups out there that are so critical to the ecosystem. And there’s the point of view of the consuming enterprises, the downstream enterprise, I think all of those play a critical role in having that seat at the table.
CRob (11:29)
I absolutely agree. So as we continue our conversation here and getting more to, think, is one of your true areas of passion.
From your perspective, you’ve seen a lot of engineers in your career and you’ve seen them become kind of strong speakers and potentially global influencers through this open source ecosystem. From your perspective, do you see active participation in like open source projects as some type of a fast track towards leadership for engineers?
Jamie Thomas (12:04)
I think it’s one of those many facets that can really improve your career trajectory. The reason I think this is that for any accomplished computer science engineer today, you really have to have the ability to influence others. You have to have the ability to influence networks. Maybe that’s outside of your organization or inside of your organization. You have to have the ability to influence your customers.
And so how do you build that kit bag of resources and skills that allow you to do that? And I think participation in an open source community gives you a lot of industry perspective.
You know, when I go to the OpenSSF, I don’t just go there and understand, of course, what my point of view is, I’m understanding the collective point of view. And that collective point of view is very interesting and fascinating. Learning from others and then having that ability to share your unique perspective with clients and even in your internal organization is a skill that many people often underestimate.
The skill of influence is something that’s really important in today’s world. And I think that you can build that. You can also strengthen your own personal presentation skills.
I’ve seen many people presenting in a lot of these forums, whether they’re presenting at one of the conferences or presenting in a governing board or presenting at one of the breakouts. And it really is, once again, an opportunity for you to build your own personal presentation skills, understand how you can represent your ideas more effectively to another organization or set of organizations. And that is something I think is critical for a lot of individuals that are pursuing a different career trajectory.
CRob (13:50)
Mm-hmm. I really appreciate that insight. If thinking about this, how important is it for an engineer to have kind of this open source pedigree, whether it’s like a recognition, like your IBM Open Innovation Awards or other types of awards? How does participating in those things help that individual stand out, especially in this age where organizations are rapidly changing and pivoting?
Jamie Thomas (14:19)
Well, thanks for bringing that up IBM does have an open innovation award that we give to individuals every year who are standouts in the participation of open communities. And I think that’s really important. And we have both executive contributions as well as non-executive contributions and I always recognize those individuals in my all hands meetings to make sure they get their name in lights a bit internally. But I think that this is particularly important for individuals who once again want to take the learning from these kind of communities and use that to more broadly influence the direction of organizations. In many cases and I was just on one of these today in fact a lot of the innovation does start in an open source format because once again it’s very easy to get your ideas out there to start seeing them scale understand what really appeals to clients and what is not then how do you take the open source kernel and then create something that is of commercial value right.
You either have to have the concept like we did with Eclipse that it’s going to enable developers to use other products more effectively, or you have to take the kernel and then become an enterprise open class support organization like what Red Hat did eventually…
CRob (15:41)
Mm-hmm.
Jamie Thomas (15:42)
Very accomplished open source curation organization. So I think for individuals to help companies like IBM or to help their team to help their little asset that they created become more successful, then this participation is absolutely critical. And without a few individuals along the way that really understand how to do this, then I think many, many rewarding projects will not get from point A to point B and be as successful as they could have been.
CRob (16:12)
Right, Yeah, I definitely agree with that. So how…
Jamie Thomas (16:17)
I mean, look at things like probably, you know, Kubernetes or many of the things that we recognize today is just we take for granted without that kind of vested participation support would they have become what they are today? I mean, Linux is the best example, of course.
CRob (16:36)
I absolutely agree. Kubernetes is another example of where we had an organization that had an idea and there were some competing ideas at the same time. And then that project was donated to a neutral foundation where all these fierce competitors could get together and work together in that space to help make the technology itself far more impactful than it ever would have been.
Jamie Thomas (17:00)
Yes. And I hear I hear behind the scenes, even though I was not part of all of that directly, that there was a little bit of storming and norming and maybe a few disagreements along the way and everything.
CRob (17:10)
Yep.
Jamie Thomas (17:11)
But eventually, you know, some really good things came out of that. And, you know, it’s like anything when you nothing, nothing really good is achieved in my mind without conversation, you know, without really having a human dialogue to understand what’s working and what’s not. Certainly big things are not achieved typically through subterfuge and so I think that is the value of a lot of these communities.
CRob (17:38)
I agree. So when you’re thinking about, again, from the developer maintainer perspective, what’s advice you would give to give a developer to pitch to their manager about spending some part of their time working upstream, hopefully in security, but participating in an upstream project? How do you help them sell that to their management?
Jamie Thomas (18:01)
Well, I think in many cases, the individual needs to take a point of view of what’s in it for my manager, right? I mean, it’s kind like when you’re trying to sell anything, right? There are certainly clear attributes that help you as an individual, right? Can improve your leadership skill, your ability to help the manager from that perspective, I think is quite valuable. Problem solving is something we often take for granted today, but it’s not always there, right? But then the other thing is what what particular.
But will the participation aid from a business perspective? And I think there’s a lot of different aspects of that. If someone’s working in the security domain, I think there’s really clear outcomes.
where their participation will benefit for the enterprise you learn so much right in terms of what you need to do. If you’re working in a particular project that is going to have downstream impacts possibly to the organization I think there’s a clear linkage there. But first of all never take for granted that everyone does understand open source.
I find that even in today’s environment, there’s a lot of upline management or senior executives perhaps don’t understand the importance of open source and open source participation. It’s kind of like the water that’s running in our house and we just think it’s gonna always be there. It’s always gonna be on, right? So building that cell package is important. It’s important.
CRob (19:30)
So from, again, your perspective, outside of having some coding skills or some other technical ability, what other types of specific things should people think about when they’re going to go engage upstream? Are there other abilities or skills they might be able to bring to bear to help upstream?
Jamie Thomas (19:52)
Well, I think that coding skills are one but don’t underestimate just basic ability to influence basic ability to bring technical perspectives together and drive a conclusion. I mean, we’ve certainly seen a lot of that in the OpenSSF right where the technical committees have really had to come together and you’ve been a big part of that to render a recommended outcome right that’s influence and getting people to agreements really important back to your Kubernetes point. Somebody had – a group of people had to get some level of agreement to move forward. So influence is really important. Having domain knowledge of things like security, of secure CICD practices, sharing that with organizations I think is really, important. That’s one of the things you know that we’re really focused on is not how do we just create best practices and tools, but how do we help other projects consume those tools at a faster rate and pace.
So individuals that have that passion, who have the ability to help teams be more successful, those are maybe some soft skills that I think a lot of projects really need.
CRob (21:04)
And I think that that’s, hear this a lot from non-developer folks that are interested in contributing is, you what could I possibly bring to the table? I’m not a coder. I don’t understand C or Rust or Go. And I tell them, you have value, you have domain expertise, you understand networking or like CI systems far better than most software engineers do because software engineers are studying the language or a particular community. They don’t necessarily have a lot of these additional skills like program management and communication.
Jamie Thomas (21:40)
Yeah, and one of the things I remember the most about, you know, one of the IBM projects I worked on WebSphere is one of the most fundamental investments we made was automating the CI-CD pipeline in a really cool way. And of course, this was 20 years ago. But I’ll remember that point, like it was yesterday, because our lives change when we achieve this automation at scale. And so I think that that kind of thing can have a huge impact on the projects today. One of things we’ve been talking about as you know with all the AI mania that’s out there these days is one thing to find the defects but how do you fix the defects and actually test them at scale?
So we all know the secret of many software projects is while we have a lot of software out there, testing them in an automated fashion even is quite a challenge for many organizations and many projects. So those people that are able to conquer those leaps across the chasm help with that CI/CD automation, help infuse security, or help create a different perspective of how to automate the test associated with not only remediating but making sure that we’re not breaking everything that’s out there that uses that particular asset. Small thing.
CRob (22:58)
Yeah, very small. So again, let’s pivot back to your conversations with enterprises and leaders broadly. How do we help move the industry from thinking about open source is something that’s consumed to something that is more of your steward? Your participant in this shared infrastructure?
Jamie Thomas (23:21)
Well, I think we have to continue what we’re doing here in this session. Really, we have to continue to provide a lot of education and perspective about what happens when you don’t do that. Right. This is, you know, it’s like, you know, my house, I do wake up every day and I expect the plumbing, the water and electricity to run. But on the other hand, if I’m not a good steward of the basic underpinnings of some of that capability, it might not always be that way. And I think there’s the same can be said about open source.
So when you consume it, you have to consume it, I think, with a recognition that it’s a critical part of your infrastructure investment. You should understand what you’re consuming. should typically I don’t think it should be accidental consumption unless you’re depending on perhaps a packaged app vendor to provide it to you. And then that could be something that you’re unaware of, right? S bombs and things like that are particularly making that more apparent, of course.
But I think if you’re a direct consumer of open source, do it with intent. And intent means that you’re responsible for what that means to your organization, both from a productivity perspective, but also from a security perspective and what you can expect from an investment point as well. One of the things that we’ve learned through the OpenSSF is not every project maintains a healthy state over a period of time. And so that’s why we’ve created this scorecard that gives organizations a perspective of whether the project is healthy.
And I think today, if you’re consuming open source, you need to be using those kind of assets to understand, are you consuming healthy projects? If not, what do you want to do about that? Right? So it’s you have to be an active steward in the maintenance of your open source strategy, just like you would have to be a steward of the maintenance of your own home.
CRob (25:21)
I love that. participating with intent and having a strategy. That’s excellent advice.
Jamie Thomas (25:25)
Yeah, it shouldn’t be an accidental consumption approach. It should be with intent.
CRob (25:36)
Right. Well, let’s move on to the rapid fire part of our talk. I have a couple wacky questions. I would just like the first answer off the top of your head, please. Blue suits or blue jeans?
Jamie Thomas (25:53)
I think both. I have a blue jacket on today. What am I supposed to say?
CRob (25:55)
Both very nice. That was kind of a leading question. Next question, mainframe or microservice?
Jamie Thomas (26:10)
Oh, both. Oh, I’m cheating on this quiz. But you know, I do have the fondness for mainframes. Here’s my little mainframe chip, you know, the chip package here. It’s like a little paperweight, right? This one is z 16. I don’t have z17. But anyway, and then microservices, I think the world does depend on microservices. Very, very important part of the architecture.
CRob (26:33)
And I heard you can run open source microservices on a mainframe.
Jamie Thomas (26:37)
That’s right, that is true.
CRob (26:40)
AI generated or hand coded?
Jamie Thomas (26:44)
Well, I think in today’s environment AI generated is becoming quite prevalent, but I do believe that developers who are standouts are gonna be those individuals that go back in there and use it to their advantage. So I think there will be humans in the loop or humans somewhere in many cases, and it’s up to the human to decide how do I use this cool innovation to my personal advantage.
CRob (27:12)
That’s amazing. And then finally, most importantly, Star Trek or Star Wars?
Jamie Thomas (27:19)
Now I have to confess that I was a Star Trek person growing up, right? I watched those cool Star Trek episodes and everything so I guess I’m more partial to Star Trek.
CRob (27:34)
There are no wrong answers, both are good, but it’s just kind of fun. I love both. I grew up on Star Wars and then Star Trek and then Star Wars changed my life in 77.
Jamie Thomas (27:43)
Well, I do like Princess Leia, of course. Being a woman, Princess Leia was a hero for all of the young ladies out there. Quite good. Good stuff.
CRob (27:53)
Absolutely. Well, and so as we wind down, Jamie, thank you for playing along. Your call to action. So if we have an enterprise that’s only consuming open source today, what’s one thing that you would suggest to them to get them to start participating?
Jamie Thomas (28:12)
I would ask everybody to think about what is your give back strategy?
Because if you’re consuming open source, but you’re not participating in open source projects, maybe with your developers, you’re not participating in an organization in terms of lending your unique perspective of your strategy and how the foundation or the open source project could help you with your strategy. You could do that even through maybe just the use of open source and beta testing, but be an active participant.
Think about consuming with intent. And what does consuming with intent mean for you as an organization?
CRob (28:54)
I love it. Thank you, Jamie Thomas, for participating in Big Thoughts Open Sources. This was a delight. Thank you very much.
Jamie Thomas (29:06)
And thank you very much, CRob. It’s always good to talk with you.
CRob (29:09)
Absolutely – and to those of you listening today, please check out the transcript, we’re gonna have some really great links and you know, stay cyber safe and sound. Bye everybody
Jamie Thomas (29:20)
Bye.


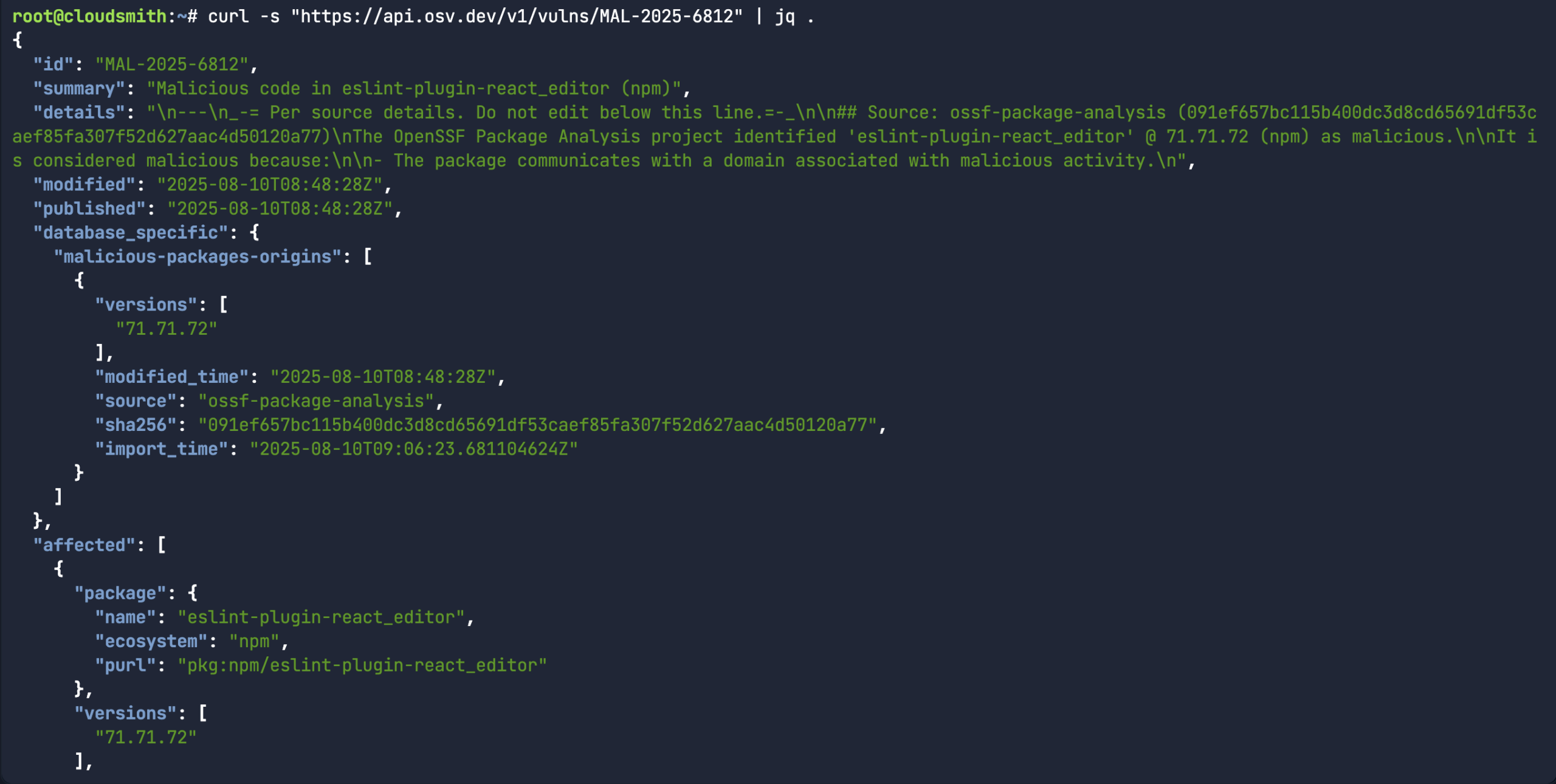 While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie:
While the above command does return a bunch of information about a specific malicious package record, it would assume you already knew what the malicious package ID was in the first place. A more common use-case for the API is to look for a specific package name/version and the associated open source upstream source (ie: 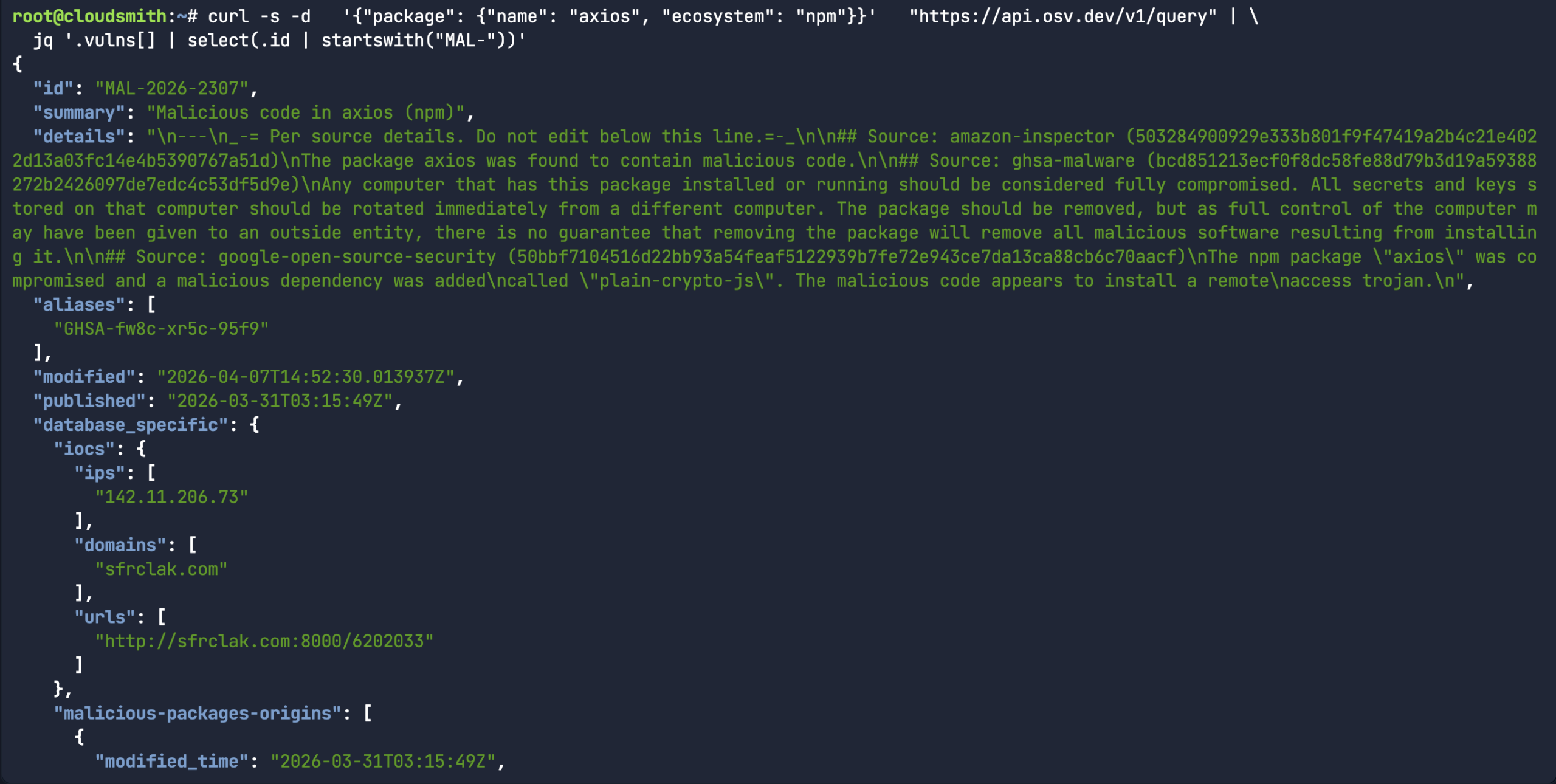 Or in the case of the
Or in the case of the 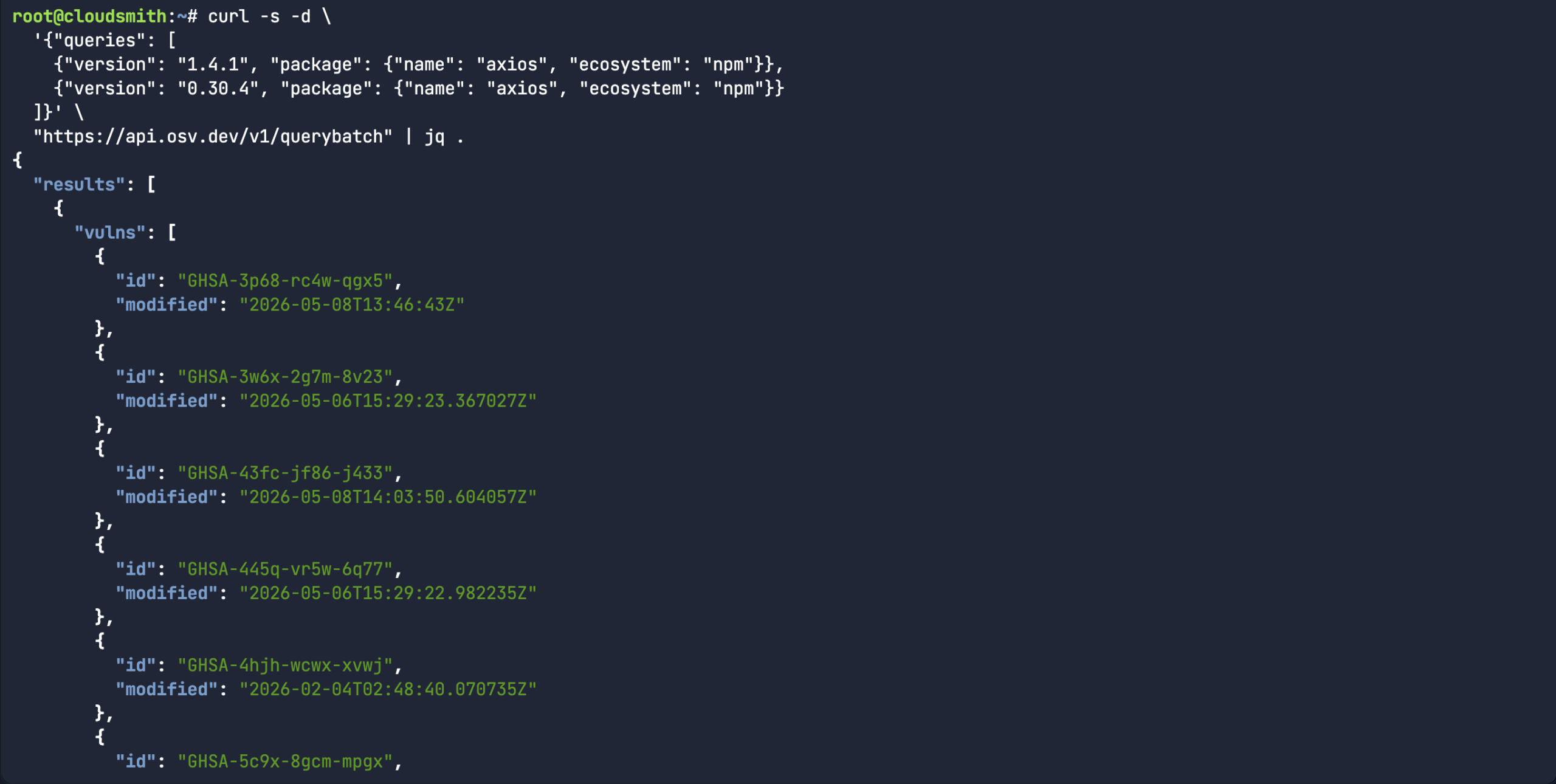
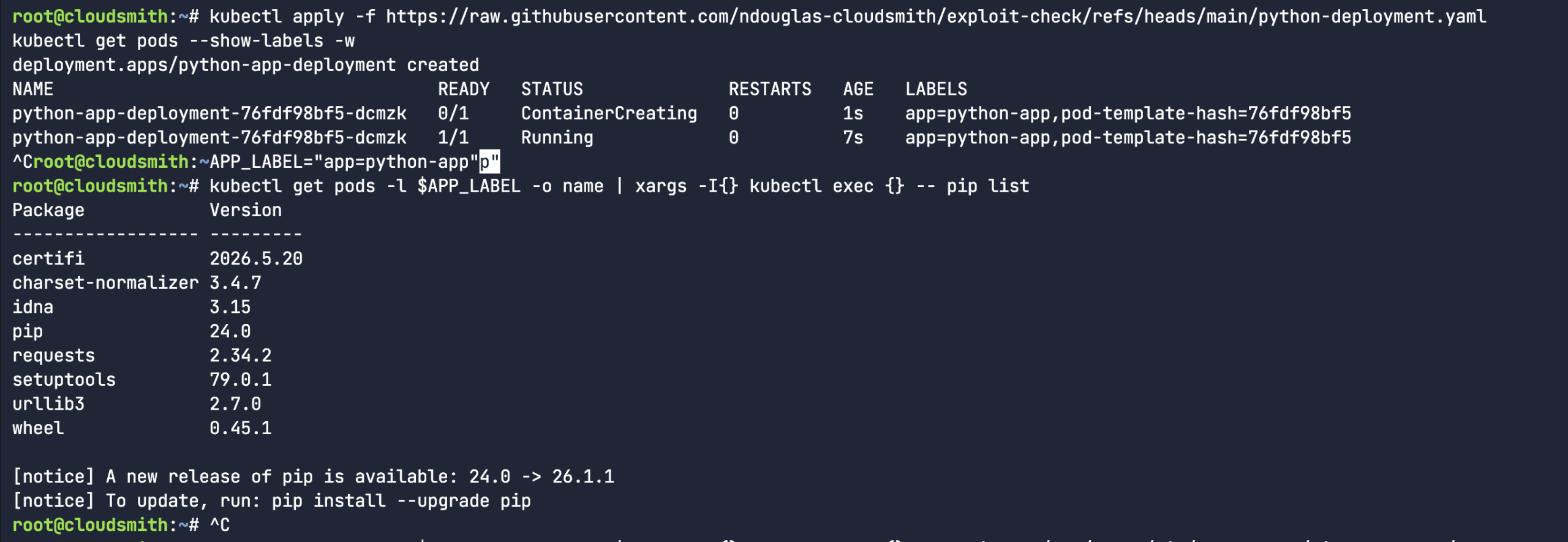 So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom
So, I proceeded to create a fake python library (rather than downloading an actual malicious software package). I mean, the package name and version were real, but I fabricated the entire content of the package. It’s a totally dummy package – as you can see from the below echo commands. Let’s see if our custom 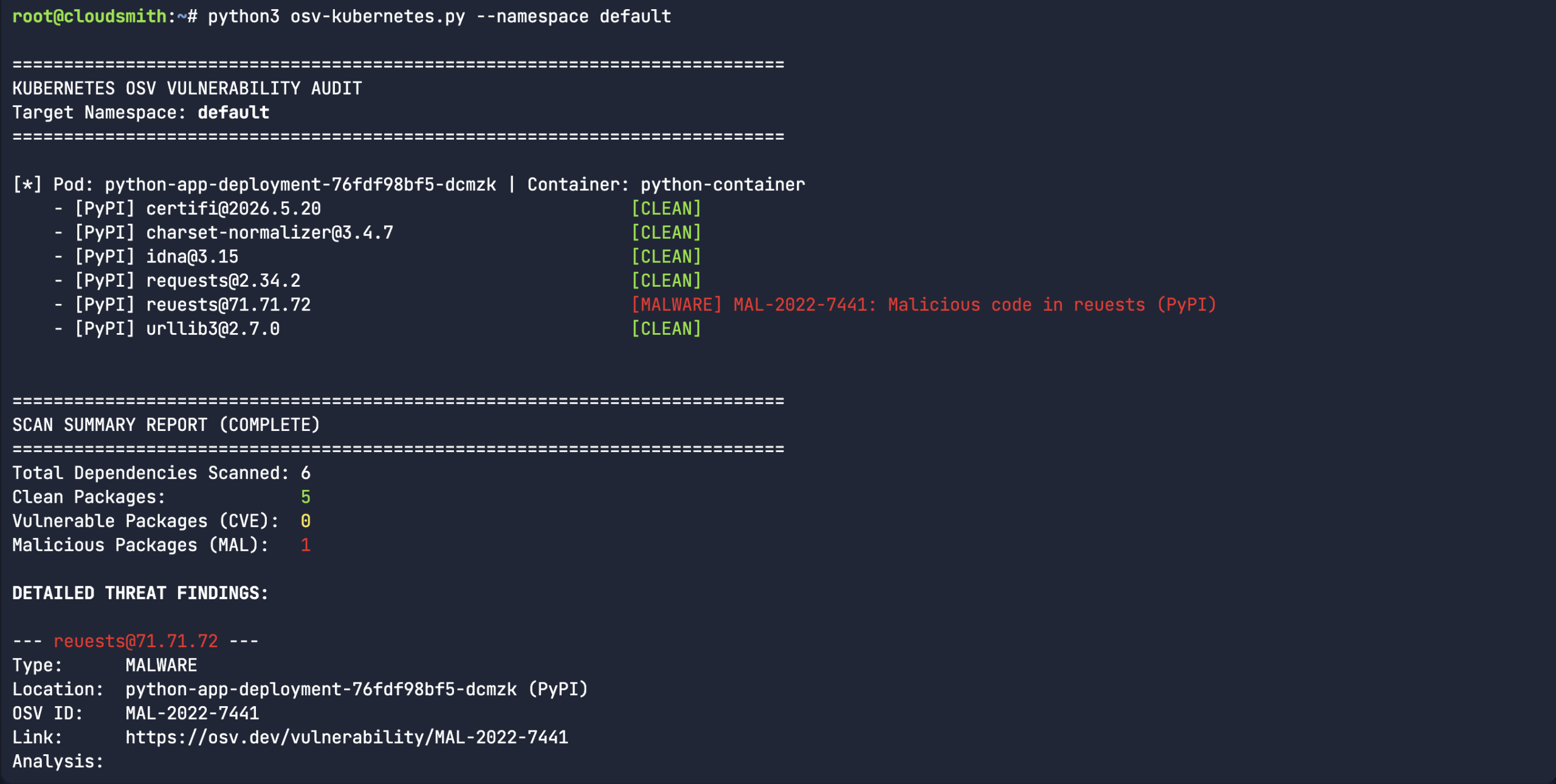 So, we created a fake typosquatted Python package. “
So, we created a fake typosquatted Python package. “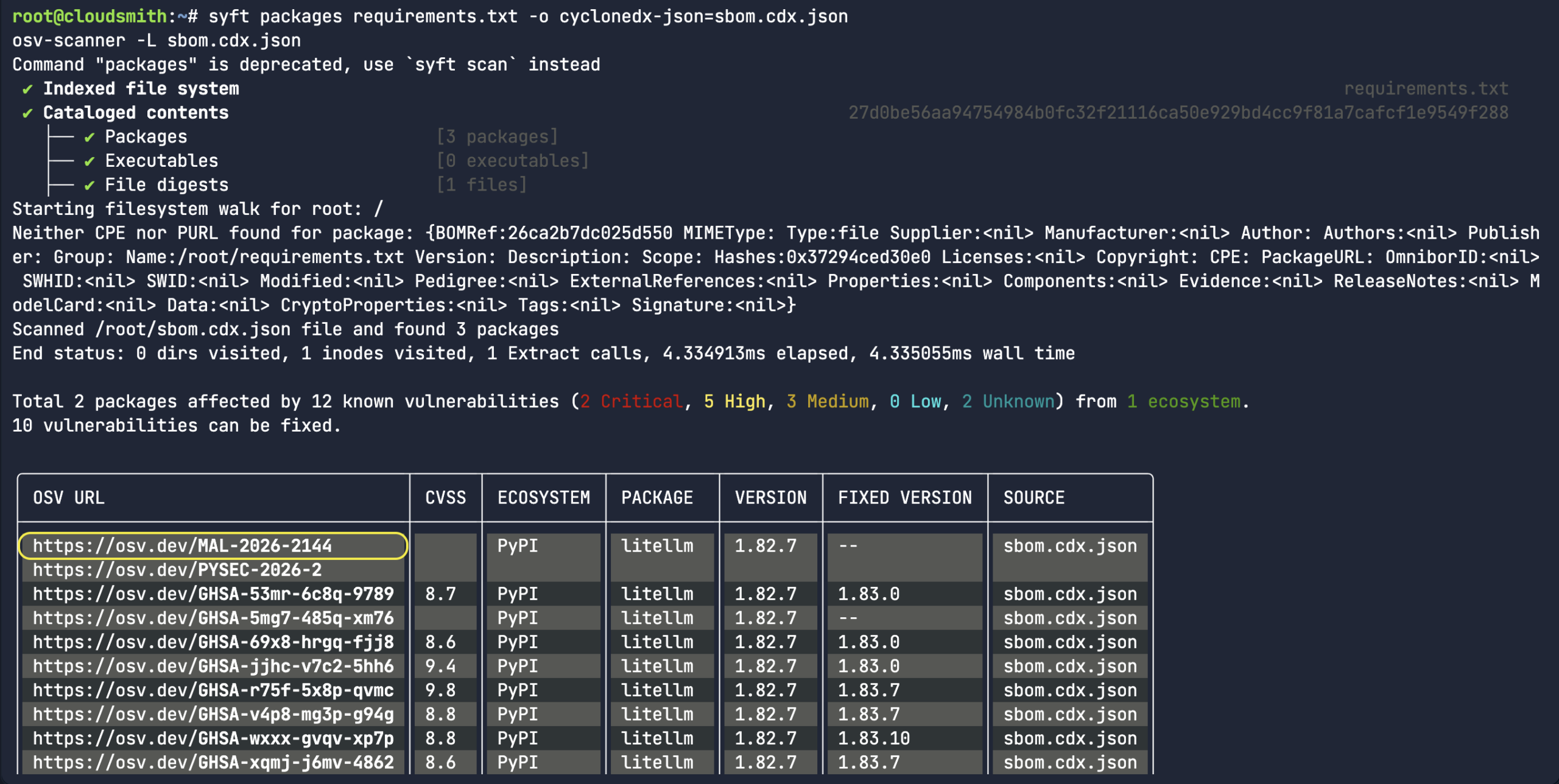
 Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.
Nigel Douglas is the Head of Developer Relations at Cloudsmith. He champions Cloudsmith’s developer ecosystem by creating compelling educational content, engaging with developer communities, and promoting software supply chain security best practices. Nigel helps build and shape the DevOps community through events, tutorials, and innovative programs.
 Tracy Ragan is the Founder and Chief Executive Officer of DeployHub and a recognized authority in secure software delivery and software supply chain defense. She has served on the Governing Boards of the
Tracy Ragan is the Founder and Chief Executive Officer of DeployHub and a recognized authority in secure software delivery and software supply chain defense. She has served on the Governing Boards of the 
 Ben Cotton is the open source community lead at Kusari, where he contributes to GUAC and leads the OSPS Baseline SIG. He has over a decade of leadership experience in Fedora and other open source communities. His career has taken him through the public and private sector in roles that include desktop support, high-performance computing administration, marketing, and program management. Ben is the author of
Ben Cotton is the open source community lead at Kusari, where he contributes to GUAC and leads the OSPS Baseline SIG. He has over a decade of leadership experience in Fedora and other open source communities. His career has taken him through the public and private sector in roles that include desktop support, high-performance computing administration, marketing, and program management. Ben is the author of  Dejan Bosanac is a software engineer at Red Hat with an interest in open source and integrating systems. Over the years he’s been involved in various open source communities tackling problems like: Software supply chain security, IoT cloud platforms and Edge computing and Enterprise messaging.
Dejan Bosanac is a software engineer at Red Hat with an interest in open source and integrating systems. Over the years he’s been involved in various open source communities tackling problems like: Software supply chain security, IoT cloud platforms and Edge computing and Enterprise messaging.
 Sarah Evans
Sarah Evans Andrey Shorov
Andrey Shorov
