
By Adam Korczynski, David Korczynski, Spencer Schrock, Laurent Simon
OpenSSF Scorecard is a tool to help open source projects reduce software supply-chain risks. Scorecard analyzes projects against a series of heuristics and generates scores from 0–10 for the project — 0 meaning that the project employs high-risk practices and 10 meaning that the project follows security best practices. Scorecard implements these heuristics in checks that each return an individual score; these are then combined into the overall Scorecard score. The scope of Scorecard is broad, which allows it to enable use cases from risk management to policy-driven decision making. In this blog post we’ll focus on a use case that allows Scorecard to be adjusted to each consumer’s individual requirements. This use case is enabled by a novel feature called “structured results”. This blog post will demonstrate the power of structured results to accomplish this individualized requirements use case.
Structured Results solves for the challenge that defining a security score from heuristics is an inherently opinionated process. Even though OpenSSF Scorecard maintains a default scoring policy, consumers of Scorecard results may value some heuristics more than others based on their own risk tolerance or policies. The current Scorecard output format lacks granularity for consumers to enable such custom risk evaluation. However, by exposing the results of the underlying heuristics, consumers could write their own checks in a much more flexible way. Instead of receiving a score, users can get granular information about a project’s security practices, and tailor the data to their needs.
This has led the OpenSSF Scorecard team, in collaboration with Ada Logics, to develop the Structured Results feature; a partnership was made possible through funding from AWS. Today we announce a pre-release of Scorecard structured results.
OpenSSF Scorecard regularly scans 1M+ repos, and makes the results available on its website. For complete usage instructions, be sure to visit the project’s README.
Introducing Probes
In this section we present the core parts of structured results, which begins with three new terms introduced to the Scorecard vocabulary:
“Structured Results” is the term we use to describe the overall feature. While the current Check format combines multiple data points to create a score, it’s difficult for users to work backwards from the score to query the individual data points. The probe format is designed to expose all of the heuristics Scorecard uses when scoring and provides them to consumers in a structured way.
“Probe” is an individual heuristic, which provides information about a distinct behavior a project under analysis may or may not be doing. For example, the Maintained check currently creates a score using a repository’s archive status, creation date, commit activity, and issue activity. All 4 of the behaviors are exposed as their own probe. Probes (44 of them) are implemented in the probes directory. Each probe is described in detail with a def.yml file that contains details such as the motivation of the probe, its possible outcomes, how it is implemented and the estimated effort necessary to remediate the probes outcome. Let’s take the example of the “archived” probe. It has the following def.yml file:
id: archived short: Check that the project is archived motivation: > An archived project will not receive security patches, and is not actively tested or used. implementation: > The probe checks the Archived Status of a project. outcome: - If the project is archived, the outcome is True. - If the project is not archived, the outcome is False. remediation: onOutcome: True effort: High text: - Non-collaborators, members or owners cannot affect the outcome of this probe. ecosystem: languages: - all clients: - github - gitlab
From this def.yml file, we can see that the probe will return either “True” or “False”. This is useful in case we want to set up a policy to act based on the results from the probe.
“Finding” is the result of an individual probe. Each finding describes the outcome of a particular probe, and optionally, a location in the repo where this behavior was observed.
We intend for individual probes to remain stable so user-defined policies remain consistent over time. In order to support this, probes will exist in an experimental, stable, or deprecated state. All probes will start in the experimental state while we gather feedback, and become stable at the time of our v5 launch. Once stable, we will fix any implementation bugs as they arise. However, any other behavioral changes would involve the creation of a new probe.
Most software today relies on third-party software which is its software supply-chain. The software supply-chain is an increasingly interesting target for malicious actors, and real-world attacks constantly reveal new techniques and attack vectors. Users need a way to identify the risks in their supply-chain, and OpenSSF Scorecard can provide visibility into adherence to known security practices to start the evaluation process. With structured results, users can tailor their own risk profiles and define their own policies against these risk profiles. Users can now act on Scorecard findings using a policy engine of their choice.
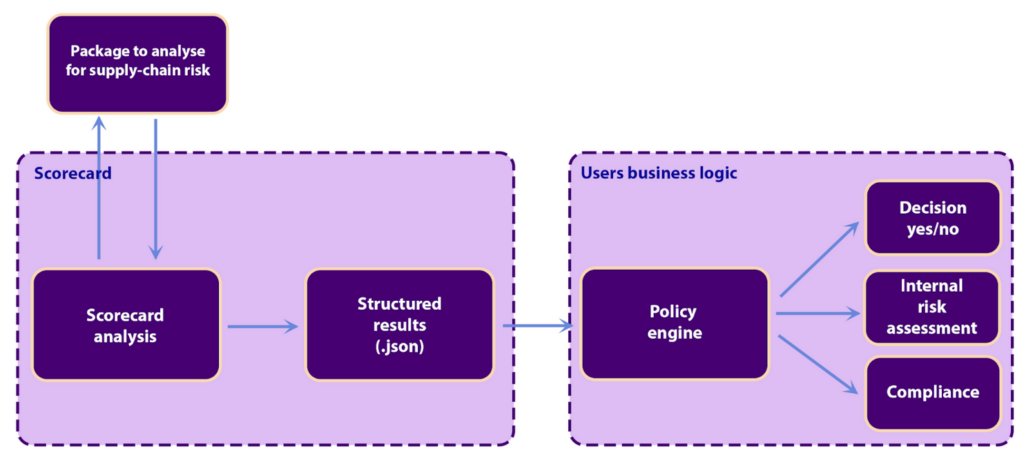
The starting point of the user’s supply-chain is one or multiple software packages. In the below diagram, this is shown in the top left corner as “Package to analyze for supply-chain risk”. The first step is to run OpenSSF Scorecard and produce a set of structured results. The next step is to pass the structured results to the user’s policy engine which will act. The policy engine can be any program with the ability to ingest .json and can be implemented in any programming language, or the user can use an existing policy engine with an established policy language such as Open Policy Agent and its Rego.
Users can access structured results today via the pre-release CLI. Structured result data will also be available via our REST API and BigQuery Table at a later date. Below, we analyze a repository http://github.com/ossf-tests/scorecard-check-vulnerabilities-open62541. To reproduce the steps below, make sure to first set up authentication.
Let’s assume we want to determine if the project has known security vulnerabilities. We run a Scorecard analysis with the hasOSVVulnerabilities probe. This probe uses data from https://osv.dev/ as its reference for known vulnerabilities.
git clone https://github.com/ossf/scorecard cd scorecard go run main.go --repo=github.com/ossf-tests/scorecard-check-vulnerabilities-open62541 --probes=hasOSVVulnerabilities --format=probe
The analysis finds that the project has one unfixed vulnerability: OSV-2020-1423. The Scorecard result also describes how this vulnerability can be ignored, if the project is certain that it is not affected by it. The text messages may be displayed to developers.
{
"date": "2024-04-11",
"repo": {
"name": "github.com/ossf-tests/scorecard-check-vulnerabilities-open62541",
"commit": "de6367caa31b59e2156f83b04c2f30611b7ac393"
},
"scorecard": {
"version": "",
"commit": "unknown"
},
"findings": [
{
"remediation": {
"text": "Fix the OSV-2020-1423 by following information from https://osv.dev/OSV-2020-1423 .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on OSV-Scanner repository.",
"markdown": "Fix the OSV-2020-1423 by following information from [OSV](https://osv.dev/OSV-2020-1423) .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml ([example](https://github.com/google/osv.dev/blob/eb99b02ec8895fe5b87d1e76675ddad79a15f817/vulnfeeds/osv-scanner.toml)) file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on [OSV-Scanner repository](https://github.com/google/osv-scanner#ignore-vulnerabilities-by-id).",
"effort": "High", "patch": "..."
},
"probe": "hasOSVVulnerabilities", "desc": "Check whether the project has known vulnerabilities",
"message": "Project is vulnerable to: OSV-2020-1423",
"outcome": "True"
},
{
"remediation": {
"text": "Fix the OSV-2020-1491 by following information from https://osv.dev/OSV-2020-1491 .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on OSV-Scanner repository.",
"markdown": "Fix the OSV-2020-1491 by following information from [OSV](https://osv.dev/OSV-2020-1491) .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml ([example](https://github.com/google/osv.dev/blob/eb99b02ec8895fe5b87d1e76675ddad79a15f817/vulnfeeds/osv-scanner.toml)) file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on [OSV-Scanner repository](https://github.com/google/osv-scanner#ignore-vulnerabilities-by-id).",
"effort": "High"
},
"probe": "hasOSVVulnerabilities", "desc": "Check whether the project has known vulnerabilities",
"message": "Project is vulnerable to: OSV-2020-1491",
"outcome": "True"
},
{
"remediation": {
"text": "Fix the OSV-2020-2328 by following information from https://osv.dev/OSV-2020-2328 .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on OSV-Scanner repository.",
"markdown": "Fix the OSV-2020-2328 by following information from [OSV](https://osv.dev/OSV-2020-2328) .\nIf the vulnerability is in a dependency, update the dependency to a non-vulnerable version. If no update is available, consider whether to remove the dependency.\nIf you believe the vulnerability does not affect your project, the vulnerability can be ignored. To ignore, create an osv-scanner.toml ([example](https://github.com/google/osv.dev/blob/eb99b02ec8895fe5b87d1e76675ddad79a15f817/vulnfeeds/osv-scanner.toml)) file next to the dependency manifest (e.g. package-lock.json) and specify the ID to ignore and reason. Details on the structure of osv-scanner.toml can be found on [OSV-Scanner repository](https://github.com/google/osv-scanner#ignore-vulnerabilities-by-id).",
"effort": "High", "patch": "..."
},
"probe": "hasOSVVulnerabilities", "desc": "Check whether the project has known vulnerabilities",
"message": "Project is vulnerable to: OSV-2020-2328",
"outcome": "True"
}
]
}
What makes structured results useful is the level of customization and flexibility they offer. Instead of all-or-nothing, 0-to-10 scores, Scorecard can measure a project against specific engineering goals, compliance, an internal risk threshold or something else. Below we present an example of an organization that has an internal policy that all its memory-unsafe software must be fuzz tested.
Example: Ensuring Memory-Unsafe Dependencies are Fuzz Tested
Consider a scenario where a developer adds a new dependency to a code base. The dependency represents a supply-chain risk that the organization can evaluate programmatically using OpenSSF Scorecard structured results. The new dependency enters the evaluation pipeline through the user’s CI system, and to assess the dependency, the user sets up a CI check against all new dependencies. In our example, the user adds a C/C++ dependency, and the user’s organization has a policy that requires all memory-unsafe dependencies to be fuzzed under the OSS-Fuzz project. This is where structured results come to action as they enable the user to implement the organization’s specific development policy within the CI pipeline. Specifically, to enforce this, the users organization has a policy that runs the Scorecard fuzzed probe against the newly introduced dependency and the organization’s CI pipeline then feeds the results from Scorecard to a policy engine that then either accepts or rejects the dependency. At a high level, the users CI looks like this:
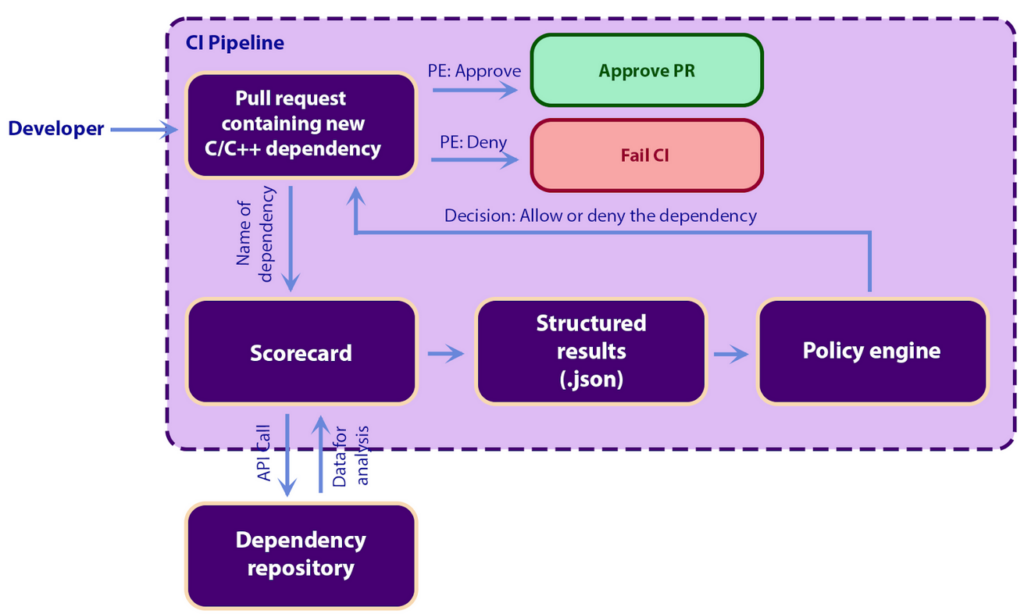 The “Scorecard” steps runs an analysis wit the fuzzed probe by way of the following three lines:
The “Scorecard” steps runs an analysis wit the fuzzed probe by way of the following three lines:
git clone https://github.com/ossf/scorecard cd scorecard SCORECARD_EXPERIMENTAL=1 go run main.go --repo=github.com/third-party/dependency --probes=fuzzed --format=probe > probes-output.json
In this example scenario, Scorecard returns the following .json string:
{
"date": "2024-04-03",
"repo": {
"name": "github.com/third-party/dependency",
"commit": "d58bfb03aab496807d8489e09da9883928465f59"
},
"scorecard": {
"version": "",
"commit": "unknown"
},
"findings": [
{
"values": {
"tool": "OSSFuzz"
},
"probe": "fuzzed", "desc": "Check that the project is fuzzed",
"message": "OSSFuzz integration found",
"outcome": “True”
},
]
}
The ”findings” array has the results from the “fuzzed” probe. In this case the OSSFuzz probe returned “True” which means that the project is integrated into OSS-Fuzz. Because the project is fuzzed, there is no remediation in the results. A simple policy script could look like the following, with the json stored in probes-output.json:
import json
with open('probes-output.json', 'r') as probes_results:
probes_data = json.load(probes_results)
for finding in probes_data["findings"]:
# We are looking for the fuzzed probe.
if finding["probe"] != "fuzzed":
continue
# Optionally, we may want to only accept OSSFFuzz as a fuzzer.
if finding["values"]["tool"] != "OSSFuzz":
continue
# The probe outcome must be"True".
# NOTE: For certain probes, you wil want the outcome to be "False" instead, e.g.
# for `hasOSVVulnerabilities` or `hasBinaryArtifacts` probes. Make sure to
# check each probe documentation!
if finding["outcome"] == "True":
print("Accept")
else:
print("Deny")
This simple policy engine returns “Accept” if the outcome from the project is fuzzed using OSSFuzz and “Deny” otherwise.
Feedback and Further Contributions
We are excited to hear feedback on structured results and learn about examples of how it is being used. Please share your thoughts on Slack at #scorecard or join our community meetings (details below).
OpenSSF Scorecard is always looking for ways to improve the project. If you are interested in helping us make OpenSSF Scorecard more usable, fixing bugs, adding new probes, or support for new ecosystems, please contribute!
Join our meetings:
The community meets biweekly on Thursdays at 1:00-2:00 PM Pacific (APAC-friendly) and every 4 Mondays at 7:00-8:00 AM Pacific (EMEA-friendly). Each meeting can be found on the OpenSSF Public Calendar.
About the Authors
 Adam is a security engineer at Ada Logics where he works on open source security. Adam performs security assessments of many high profile open source projects and has published more than 20 security assessment reports of open source projects in recent years, and reported numerous CVEs for high profile projects such as Sigstore, Golang, containerd, Ethereum, Istio and more.
Adam is a security engineer at Ada Logics where he works on open source security. Adam performs security assessments of many high profile open source projects and has published more than 20 security assessment reports of open source projects in recent years, and reported numerous CVEs for high profile projects such as Sigstore, Golang, containerd, Ethereum, Istio and more.
 David is a security engineer at Ada Logics where he leads security tool development efforts. This includes particular focus on open source fuzzing, and David is an avid contributor to OpenSSF’s Fuzz Introspector project as well as the open source fuzzing service OSS-Fuzz.
David is a security engineer at Ada Logics where he leads security tool development efforts. This includes particular focus on open source fuzzing, and David is an avid contributor to OpenSSF’s Fuzz Introspector project as well as the open source fuzzing service OSS-Fuzz.
 Spencer Schrock is a software engineer on the Google Open Source Security Team, where he works on Software Supply Chain Integrity for both open source and Google. He is a maintainer of the OpenSSF Scorecard project.
Spencer Schrock is a software engineer on the Google Open Source Security Team, where he works on Software Supply Chain Integrity for both open source and Google. He is a maintainer of the OpenSSF Scorecard project.
 Laurent is a security engineer in the Open Source Security Team (GOSST) at Google, where he works on Software Supply Chain Integrity for both open source and Google. He contributes to OpenSSF projects such as Scorecard, Sigstore, SLSA.
Laurent is a security engineer in the Open Source Security Team (GOSST) at Google, where he works on Software Supply Chain Integrity for both open source and Google. He contributes to OpenSSF projects such as Scorecard, Sigstore, SLSA.